

OGQ GYN Developers Day는 OGQ GYN의 모델 개발 과정 및 논문 등을 많은 기업 분들께 발표하는 자리로, 매월 마지막 주 수요일에 진행되고 있습니다.
이번 컨퍼런스에서는 Low Memory Network인 MCUNet, MCUNetV2에 대하여 발표했습니다.
Contents
Conference 개요
•
일시 : 2022년 11월 30일 13:00 ~ 14:00
•
장소 : Zoom 미팅
•
참여기업 (가나다순)
◦
베스트디지탈 BEST DIGITAL
◦
아이닉스 Eyenix
◦
웹게이트 WEBGATE
◦
트루엔 TRUEN
•
순서
1.
참여 업체 소개
2.
OGQ GYN 발표
•
사회자: OGQ GYN 우재현 연구원
•
발표자: OGQ GYN 정재희 연구원
3.
Q&A
1. Previous Presentation Summary
지난 컨퍼런스에서는 Semantic Segmentation을 위한 Transformer를 Knowledge Distillation으로 학습시키는 방법은 TinyViT에 대해서 소개했습니다.
1-1. Transformer
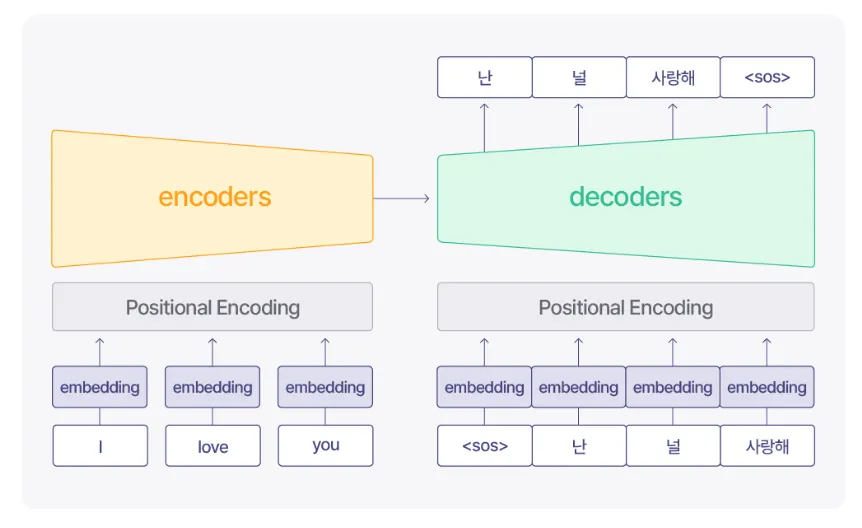
•
Transformer는 NIPS 2017에 accept된 Attention is All you Need라는 논문에서 제안된 기법입니다.
•
주로 기계번역, 챗봇 등 자연어 처리 부문에서 많이 사용되었습니다.
•
각 단어를 임베딩하고, Positional Encoding으로 시퀀스 내 단어들의 위치정보와 함께 시퀀스를 한번에 모델의 입력으로 사용합니다.
•
position 정보까지 함께 입력받을 수 있기 때문에, 단어를 재귀적으로 처리했던 RNN 계열 접근법의 한계에서 벗어나 빠른 학습이 가능합니다. 또한, 기본적으로 CNN을 사용하지 않습니다.
1-2. ViT

•
ViT는 Vision Transformer로, Transformer를 Vision 부문에 적용시켰습니다.
•
하지만 큰 파라미터 수를 필요로 하는 한계가 존재하여 edge device, mobile에서 사용이 어렵습니다.
◦
큰 모델을 큰 데이터셋으로 학습시키면 일반적으로 성능이 향상되지만, 작은 모델을 큰 데이터셋으로 학습시키면 일반적으로 under-fitting이 발생합니다.
◦
TinyViT의 저자는 작은 모델이 큰 데이터셋으로부터 지식을 흡수할 수 있는 방법에 대해 고민하였습니다.
1-3. TinyViT
-9.png&blockId=8d9dda57-5001-4f57-bd1a-b2f417950c26)
효율적으로 teacher의 output과 augmentation을 저장하는 TinyViT의 저장 기법을 나타냅니다.
•
TinyViT는 기존의 KD 학습을 느리게 하는 요인 두 가지를 해소하였습니다.
◦
teacher의 output과 입력에 대한 augmentation을 저장하는 기법을 사용하여 teacher 모델을 로드한 채 student의 학습을 진행한다는 점을 해결하였습니다.
◦
distillation loss를 계산할 때 일반적으로 soft한 정도를 조절하는 파라미터 에 대한 연산을 없애고 일반적인 Cross Entropy loss를 사용합니다.!
-12.png&blockId=3671fd3f-8687-4992-a578-4ebe81323788)
•
TinyViT는 타 method들보다 적은 파라미터에서 높은 성능을 제공하는 좋은 trade-off를 제공합니다.
2. Low Memory Network
-12x.png&blockId=a403f2a7-5fb0-43e8-a262-c865560d723b)
•
딥러닝 모델을 학습/사용할 때에는 연산에 사용되는 값을 메모리에서 연산장치로, 연산장치에서 메모리로 복사하는 과정이 끊임없이 일어납니다.
2-1. Problem
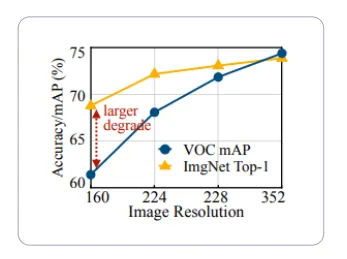
이미지 해상도에 따른 데이터셋 별 성능
•
네트워크가 많은 메모리를 필요로 할 때의 문제점은 다음과 같습니다.
◦
메모리 대역폭에 비하여 많은 양의 값을 읽고 써야 하기 때문에 병목현상이 발생하여 inference time에 영향을 줄 수 있습니다.
◦
메모리 용량에 따른 input image의 해상도에 제약이 커지기 때문에 고해상도의 input image를 필요로 하는 object detection과 같은 task에서 성능을 높이기 어렵습니다.
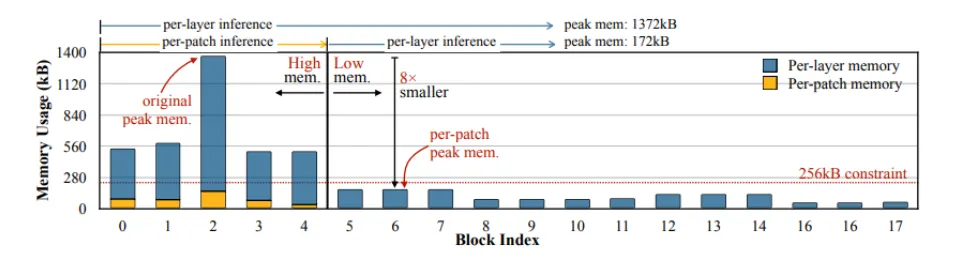
MobileNetv2의 네트워크 각 stage 별 메모리 사용량
•
MobileNet과 같은 기존 lightweight 네트워크들은 연산량을 줄이는 데에만 집중하고 메모리 병목을 해소하지 않기 때문에 edge device 등의 환경에서 적용하기 어려웠습니다.
3. MCUNet
MCUNet은 NIPS2020에 accept된 논문으로, 네트워크 연산 엔진을 개선하여 메모리 사용량을 줄였습니다.
3-1. Introduction
-22x.png&blockId=39715961-f0a6-4245-8a9e-d9f9c2d49c9c)
기존 방식, input에 대한 연산 결과를 새로운 공간에 할당한다.
-32x.png&blockId=1385ef16-dc2e-4892-a607-7aceb75e0399)
MCUNet, 연산이 끝난 결과를 input 메모리에 덮어쓰기하여 공간을 아낀다.

•
MCUNet은 연산 output에 대하여 새로운 메모리 공간을 할당하는 것이 아니라 더이상 사용하지 않는 input 메모리에 덮어쓰기하여 메모리 사용량을 줄였습니다.
•
MCUNet은 MobileNetv2 대비 3.5배 더 적은 양의 메모리를 사용합니다.
3-2. Experiments
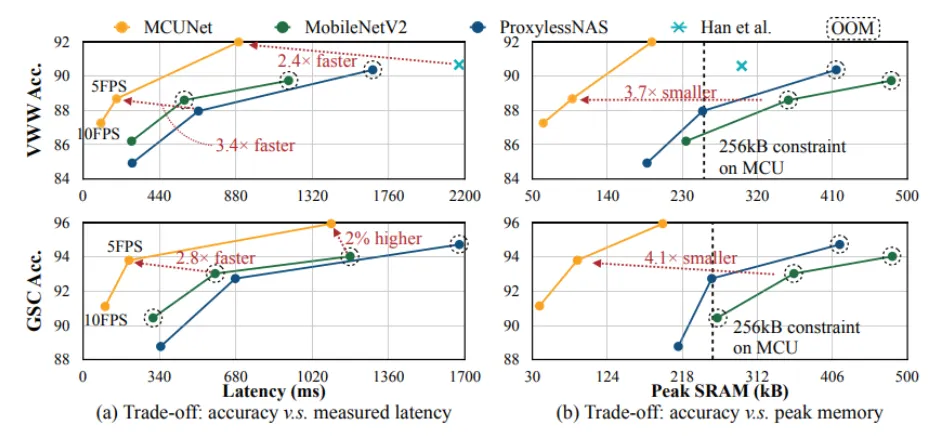
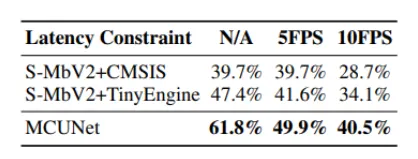

•
MCUNet은 더 적은 메모리와 inferernce time을 사용하면서 그에 비해 더 높은 성능을 내고 있어 좋은 trade-off를 제공합니다.
•
real-time에서도 적용하기 쉽고, 적은 메모리 사용량으로 인해 edge device같은 환경에서도 쉽게 적용할 수 있습니다.
4. MCUNetV2
MCUNetV2는 NIPS2021에 accept된 논문으로, 네트워크 구조 차원에서 적용시킬 수 있는 메모리 절약 방법을 소개합니다.
4-1.Introduction
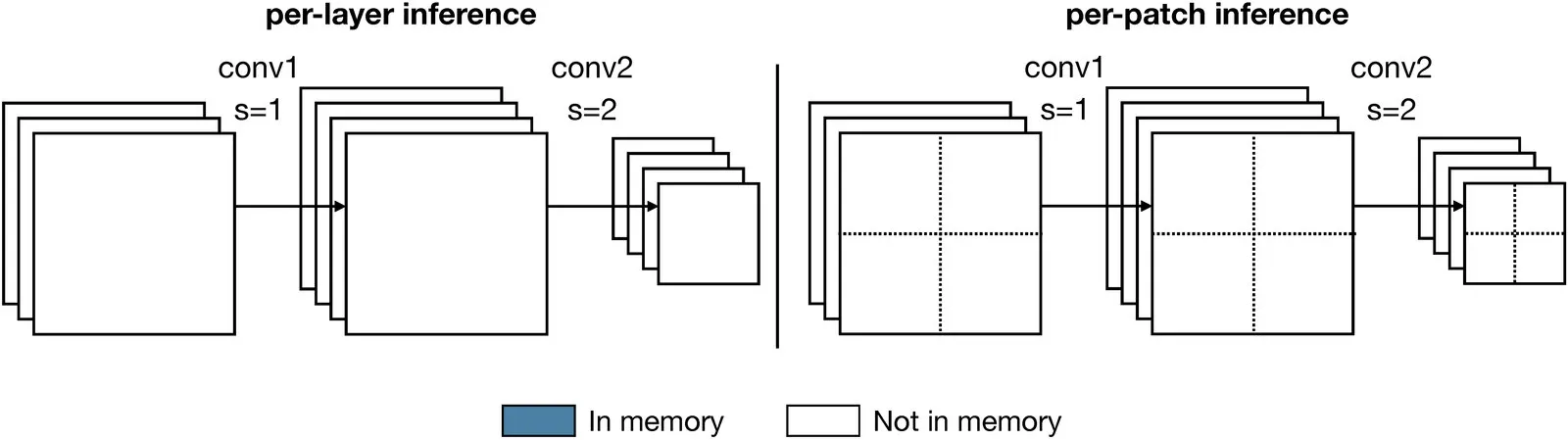
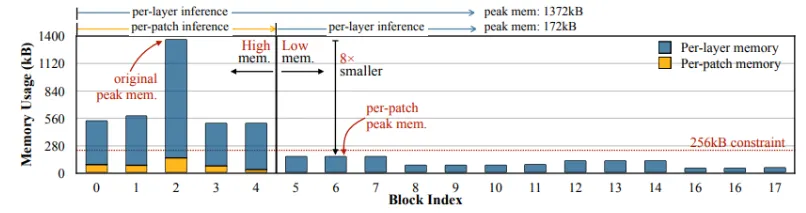
파란색: per-layer, 노란색: per-patch
•
MCUNetV2는 layer 단위로 이루어지던 기존 convolution 연산을 patch 단위로 나누어서 수행하는 방식입니다.
•
하나의 layer 전체를 메모리에 올리는 대신 patch 단위로 일부만 메모리에 올리기 때문에 메모리를 보다 적게 사용합니다.
•
초기 layer에서 메모리를 많이 사용하는 MobileNetV2의 초반 layer에 per-patch inference를 적용시키게 되면 최대 메모리 사용량이 8배 감소하는 모습을 확인할 수 있습니다.
4-2. Experiments
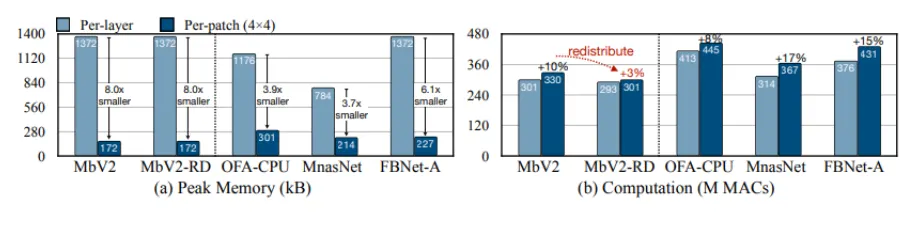
•
MCUNetV2는 네트워크 구조가 아닌 연산 방식을 제안하기 때문에 MobileNetV2 등 기존에 있던 네트워크에 쉽게 적용할 수 있습니다.
•
다른 네트워크에 MCUNetV2의 per-patch inference를 사용하였을 경우 연산량은 최대 20%정도 늘어나는 것에 비해 메모리 사용량은 3.7~8.0배 줄어들기 때문에 효율적입니다.
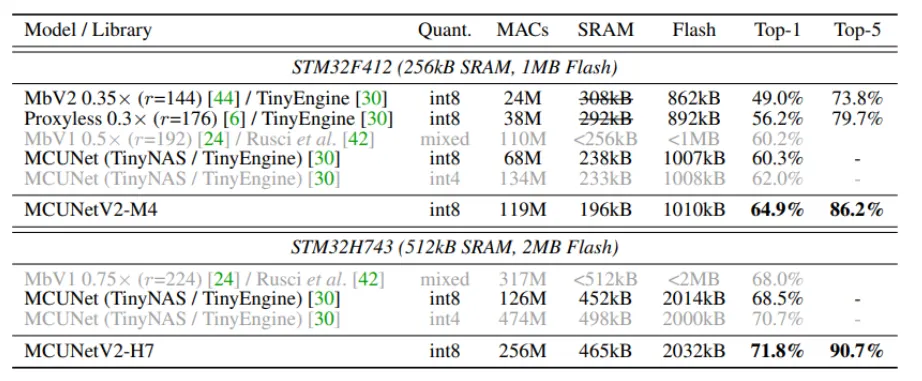
ImageNet classification result

Pascal VOC object detection 결과 (마이크로컨트롤러에서 테스트)
•
마이크로컨트롤러와 같은 메모리의 용량이 제한된 환경에서도 쉽게 적용할 수 있습니다.
•
특히 object detection과 같은 task에서는 메모리 사용량이 적어 고해상도의 이미지를 사용할 수 있기 때문에 성능 손실이 적은 것을 확인할 수 있습니다.
List
Search




OGQ GYN의 기술블로그를 비상업적으로 사용 시 출처를 남겨주세요.
상업적 용도를 원하실 경우 문의 부탁드립니다.
E-mail. tech@gynetworks.com
 OGQ Corp. All right reserved.
OGQ Corp. All right reserved.