

OGQ GYN Developers Day는 OGQ GYN의 모델 개발 과정 및 논문 등을 많은 기업 분들께 발표하는 자리로, 매월 마지막 주 수요일에 진행되고 있습니다.
이번 세미나에선 ViT-CoMer 논문을 소개합니다.
Contents
세미나 개요
•
일시 : 2024년 06월 05일 13:00 ~ 14:00
•
장소 : Zoom 미팅
•
참여기업 (가나다순)
◦
베스트디지탈 BEST DIGITAL
◦
웹게이트 WEBGATE
◦
한국씨텍
•
순서
1.
참여 업체 소개
2.
OGQ GYN 발표
•
사회자: OGQ GYN 우재현 연구원
•
발표자: OGQ GYN 우재현 연구원
3.
Q&A
1. Previous Presentation Summary
지난 MobileNet v1, v2, v3에 대해 리뷰하는 시간을 가졌습니다.
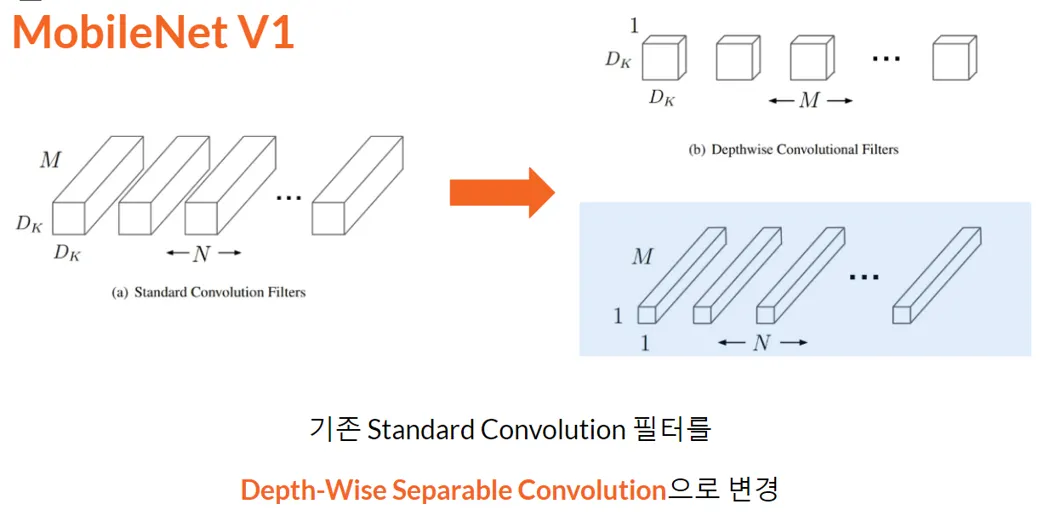
•
Standard Convolution 필터를 Depth-Wise Separable Convolution으로 변경
•
연산량과 성능 사이의 trade-off에서 적은 성능 손실로 연산량을 획기적으로 줄임
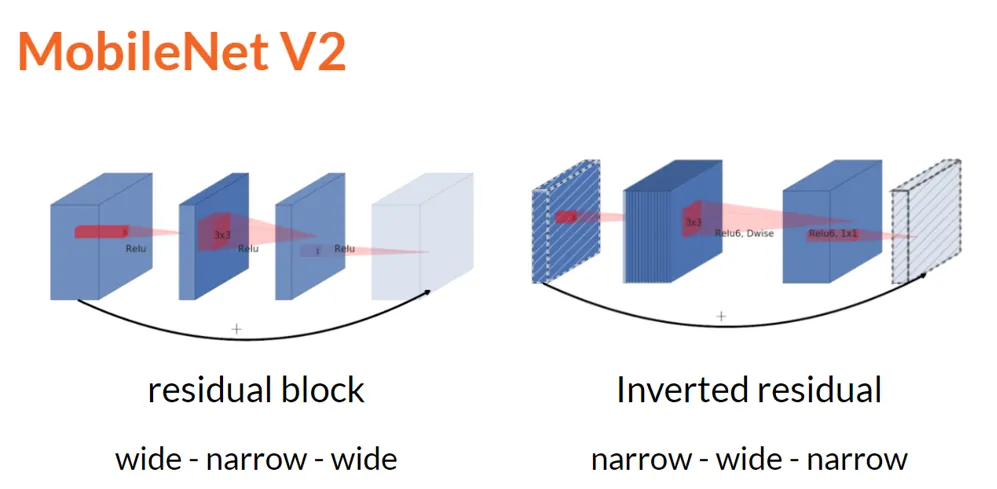
•
Inverted residual를 제안
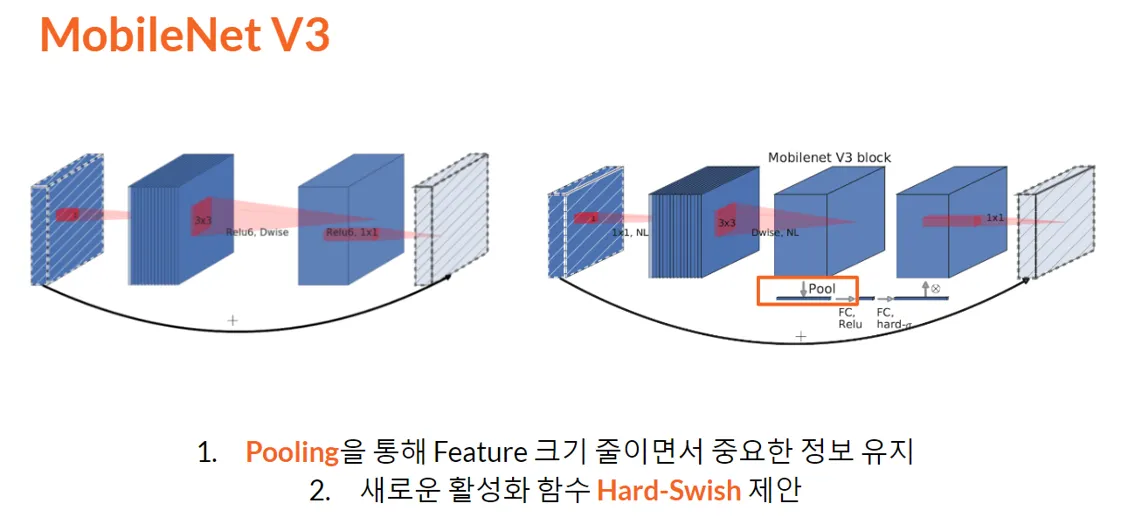
•
Inverted residual 에 residual connection으로 Pooling으로 feature의 중요한 정보를 추출하였음
•
Hard-Swish 제안
•
NAS 적용
이상으로 Mobilenet v1, v2, v3의 주요 포인트들이 있었습니다.
2. Problem
이번에는 CVPR Highlight 논문인 ViT-Comer 에 대해서 알아보려 합니다.
알아보기 전에 ViT는 무엇인지, CNN가 무엇이 다른지 그 배경을 알아볼 필요가 있습니다.
과거에는 이미지에 대해 Convolution을 도입하여 딥러닝 모델을 만드는 것이 보편화되어 있었으며 Transformer는 단어, 문장과 같은 text를 이해할 수 있는 딥러닝 모델을 만드는 것이 보편화되었습니다.
ViT란?
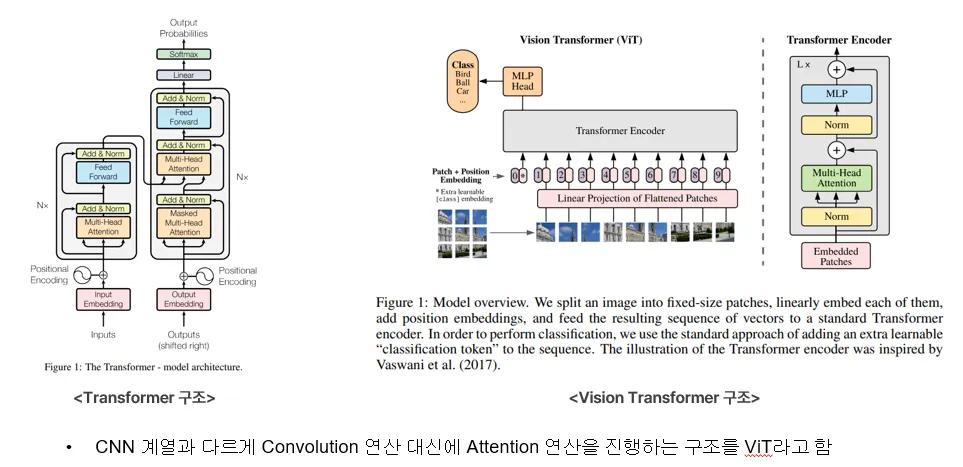
ViT는 ‘성능이 좋은 Transformer를 이미지에 대해 적용할 수 있지 않을까?’ 라는 물음에서 시작된 모델입니다.
ViT의 이름 유래 또한 Transformer의 이름 앞에 Vision이 들어갑니다.
Vision Transformer(ViT)는 이미지를 Patch 단위로 분리하여 Transformer의 입력으로 들어갈 수 있는 이미지 Patch는 백터화와 Position Embedding이 적용되었습니다.
다음과 같이 구성한 모델이 기존의 CNN 보다 높은 성능을 달성함으로써 ViT 모델이 이미지 관련 문제를 해결할 수 있는 큰 기준으로 자리잡게 됩니다.
ViT-Comer Abstract
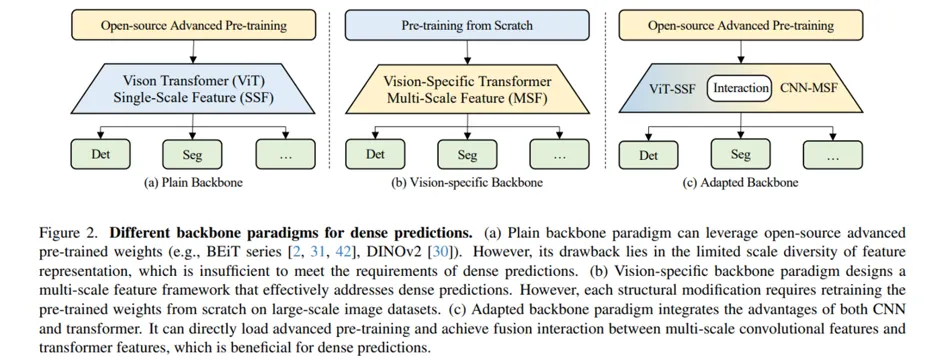
ViT와 CNN은 각각의 장단점이 있으며, 둘의 가장 큰 차이는 파라미터와 bias의 유무입니다.
•
ViT는 큰 파라미터와 bias가 없으며 bias가 없기 때문에, 특정 데이터셋의 편향을 학습하지 못하므로 학습 시에 아주 많은 학습데이터를 필요로 합니다.
•
CNN은 비교적 적은 파라미터와 bias가 있으므로 일반적인 학습에 용이합니다.
ViT-Comer는 ViT와 CNN의 각 장점을 활용할 수 있는 방안에 대해 얘기합니다. 아래 두 가지가 논문의 가장 큰 contribution입니다.
•
ViT뿐만 아니라 Convolution Multi-scale feature를 활용하도록 ViT에 CNN branch를 추가
•
기존의 ViT에 Convolution Feature를 적용하려는 시도는 많았지만 Open-source의 weight를 사용하며 Multi-scale feature를 사용할 수 있는 기술을 적용
2. Method
다음으로는 실제로 어떻게 해당 모델을 구현했는지 방법입니다.
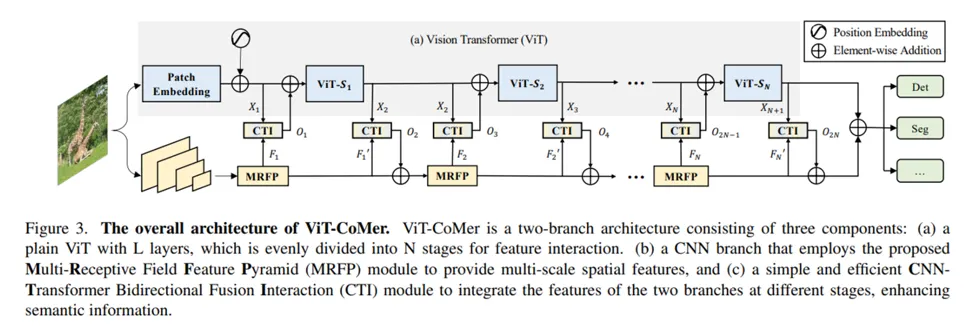
•
Open-Source weight를 활용할 수 있도록 ViT branch의 ViT는 구조 변경없이 그대로 사용하였습니다.
•
MRFP (Multi-Receptive Field Feature Pyramid module)와 CTI (CNN-Transformer Bidirectional Fusion Interaction module)를 제안하여 CNN feature와 Transformer feature 결합하여 사용합니다.
•
CTI를 bi-directional 설계를 통해 CNN feature와 ViT feature를 결합하여 CNN/ViT Branch에 붙였습니다.
성능에 큰 기여를 한 MRFP, CTV 모듈을 살펴보면,
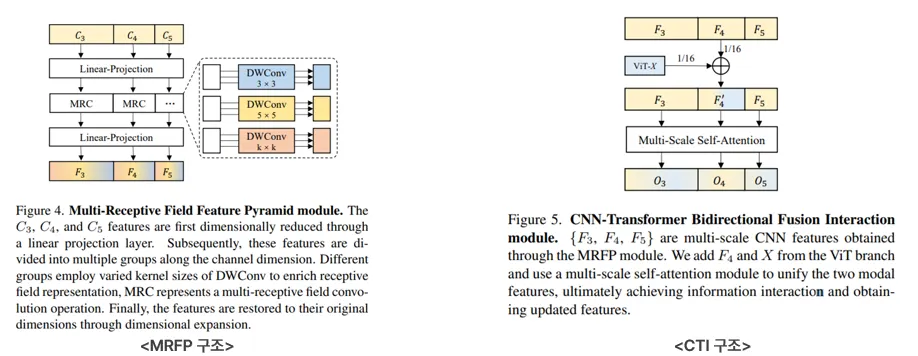
•
MRFP는 MRC(Multi Receptive Field Convolution)을 적용하는 구조를 제안합니다.
◦
DepthWise Convolution을 활용하여 연산량 및 k * k 필터를 사용하여 multi-feature 정보를 얻음
•
CTI는 CNN-Transformer feature를 Interaction하기 위한 모듈입니다.
◦
F_4 feature를 기준으로 ViT와 feature를 결합한 후에 Multi-Scale Self-Attention을 통해 F_3, F_5에도 ViT Information을 결합하였음
•
CTI를 bi-directional 설계를 통해 CNN feature와 ViT feature를 결합하여 CNN/ViT Branch에 붙였습니다.
3. Result
다음으로는 Method로 구현한 모델에 대한 Result입니다.
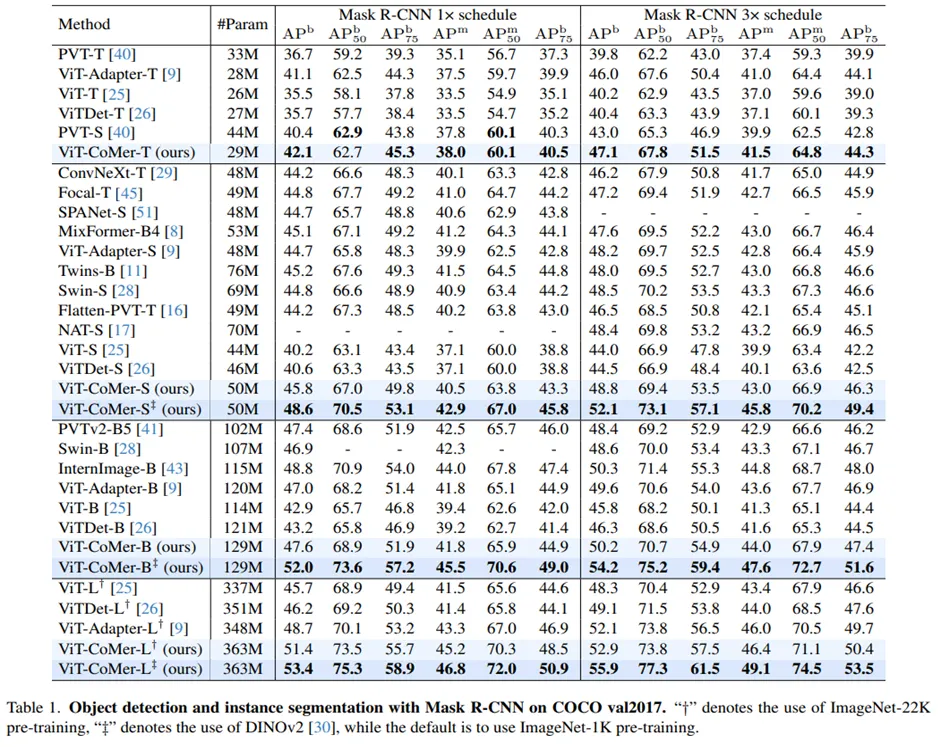
•
Object Detection과 Instance Segmentation에서 제안한 ViT-Comer가 ViT에 비해 성능이 훨씬 높습니다.
•
DINOv2 weight를 사용했을 때는 훨씬 성능이 높아집니다.
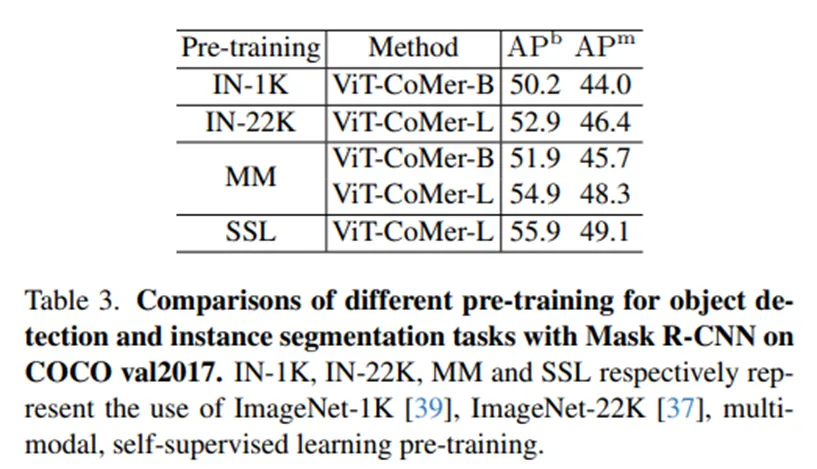
•
MM - DeiT weight, SSL – Dinov2 weight
: Open-Source Weight를 사용하는 것이 확실히 성능이 높습니다.
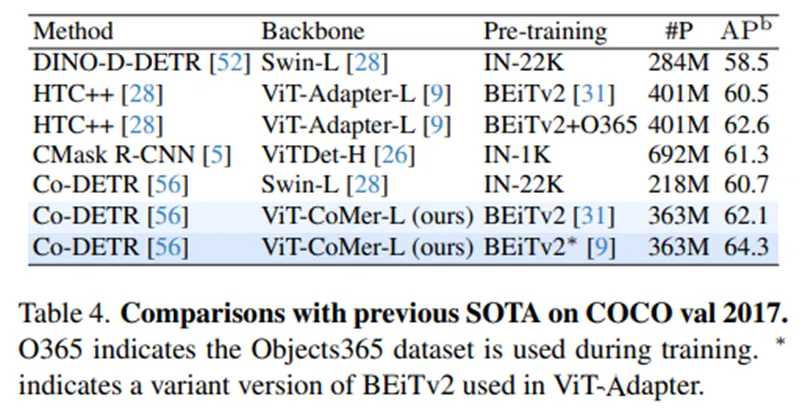
•
ViT 계열의 다른 구조들과 비교했을때, 성능이 더 높습니다.
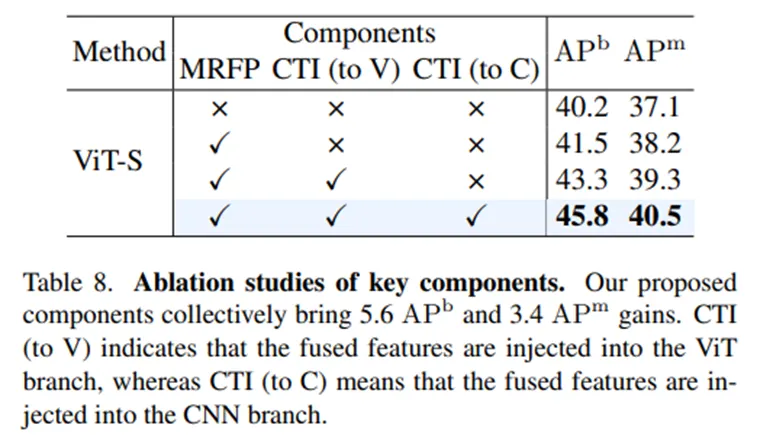
•
MRFP, CTI 구조가 성능 향상에 기여했으며 특히 CTI를 bi-directional 하게 설계한 것이 가장 성능 향상이 큽니다.
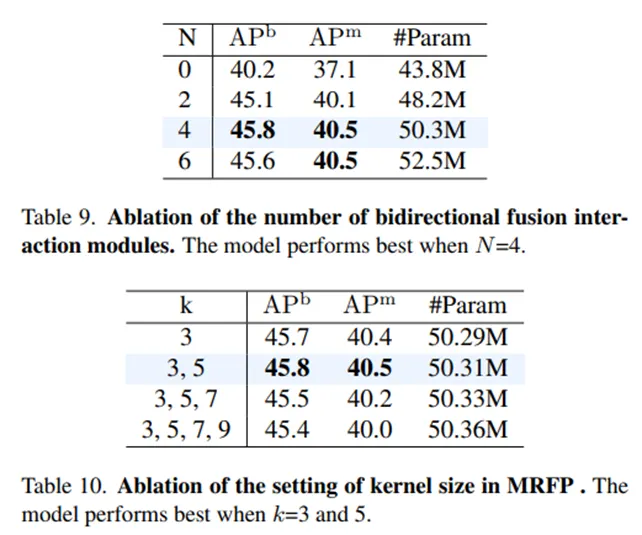
•
Table 9 : Interaction Modules (MRFP + CTI) 구조를 반복한 회수에 따른 성능으로 N이 증가한다고 계속 성능이 높아지진 않습니다.
•
Table 10 : MRFP의 MRC의 Convolution kernel size에 따른 모델 결과로 k를 3,5 로만 구성했을때의 성능이 제일 높습니다.
3. Result
•
본 논문은 Pre-trained weight를 사용할 수 있는 standard ViT base인 ViT-CoMer를 제안합니다.
•
Multi-Scale Convolutional feature modul를 Adapter 처럼 붙여서 CNN의 장점을 효과적으로 활용하였습니다.
•
ViT-CoMer은 Detection, Segmentation와 같은 다양한 task에서 기존 ViT base 모델들보다 우수한 성능을 보여주고, 특히 pre-trained weight를 활용했을때 SOTA 성능을 보여줍니다.
List
Search




OGQ GYN의 기술블로그를 비상업적으로 사용 시 출처를 남겨주세요.
상업적 용도를 원하실 경우 문의 부탁드립니다.
E-mail. tech@gynetworks.com
 OGQ Corp. All right reserved.
OGQ Corp. All right reserved.