

OGQ GYN Developers Day는 OGQ GYN의 모델 개발 과정 및 논문 등을 많은 기업 분들께 발표하는 자리로, 매월 마지막 주 수요일에 진행되고 있습니다.
이번 컨퍼런스에선 Knowledge Distillation 최신 논문 중 하나인 TinyViT에 대해 발표했습니다.
Contents
Conference 개요
•
일시 : 2022년 10월 26일 13:00 ~ 14:00
•
장소 : Zoom 미팅
•
참여기업 (가나다순)
◦
베스트디지탈 BEST DIGITAL
◦
아이닉스 Eyenix
◦
웹게이트 WEBGATE
◦
트루엔 TRUEN
•
순서
1.
참여 업체 소개
2.
OGQ GYN 발표
•
사회자: OGQ GYN 우재현 연구원
•
발표자: OGQ GYN 오다연 연구원
3.
Q&A
1. Previous Presentation Summary
지난 컨퍼런스에서는 Knowledge Distillation과 최신 논문인 CWD를 소개하고, 개발 현황에 대해 발표했습니다.
1-1. Knowledge Distillation
_Tech_(7)-6.png&blockId=2ebd6656-2e78-468e-8b1f-60eefe772738)
•
KD는 학습이 된 큰 네트워크의 출력 결과를 추가 label로 활용하여 작은 모델을 학습시키는 기법입니다.
•
이 때, 큰 네트워크를 teacher, 작은 네트워크는 student라고 부릅니다.
1-2. Channel-wise Knowledge Distillation
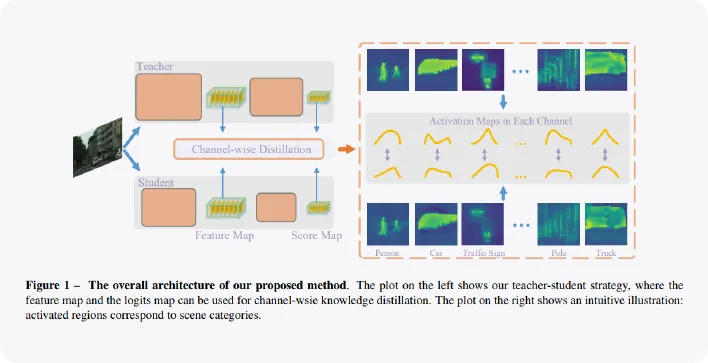
•
ICCV 2021에 제출되어 2021년 SOTA를 달성한 Semantic segmentation을 위한 Knowledge Distillation 기법입니다.
•
모델이 생성하는 이미지와 객체의 특징이 담긴 feature map에 대해 각 픽셀 별로 teacher의 출력을 따라할 수 있도록 학습합니다.
1-3. Development Status
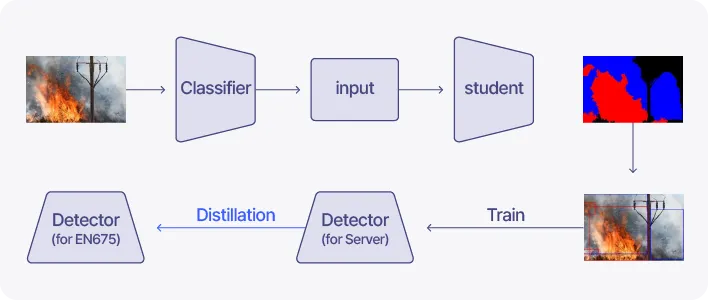

•
RS+EPM은 2022년 기준 모든 데이터셋 기준 WSSS에서 가장 높은 성능을 달성하고 있습니다.
•
자체 기술인 RS+EPM을 활용하여 박스 정보가 없는 데이터에 대해 pseudo box label을 생성하여 학습을 진행하고 있습니다.
•
또한, KD 기법을 적용하여 Server 타입과 EN675 타입의 성능 격차를 줄이려 하고 있습니다.
2. Background
2-1. Knowledge Distillation (KD)
-1.png&blockId=f95031ba-efc1-4d3c-b621-6ba37b1df392)
•
일반적인 모델의 경우 모델의 output과 정답지의 label 간의 Loss를 개선하여 모델이 정답을 맞출 수 있도록 학습합니다.
•
KD 기법은 학습된 네트워크를 Teacher 모델로 두고, Teacher 모델의 출력과 Student 모델의 출력의 Loss를 추가로 도입하여 Teacher의 지식을 증류합니다.
2-2. Vision Transformer(ViT)
Trnaformer
-2.png&blockId=8f4301ec-7fa2-46be-a970-7af556c12f9d)
•
Transformer는 NIPS 2017에 accept된 Attention is All you Need라는 논문에서 제안된 기법입니다.
•
주로 기계번역, 챗봇에 사용됩니다.
-3.png&blockId=0ca9d130-febb-47f9-a552-773dad3bda69)
•
각 단어를 임베딩하고, Positional Encoding으로 시퀀스 내 단어들의 위치정보와 함께 시퀀스를 한번에 모델의 입력으로 사용합니다.
•
position 정보까지 함께 입력받을 수 있기 때문에, 단어를 재귀적으로 처리했던 RNN 계열 접근법의 한계에서 벗어나 빠른 학습이 가능합니다. 또한, 기본적으로 CNN을 사용하지 않습니다.
Vision Transformer (ViT)
-4.png&blockId=99e906b1-ba84-4cf7-80a8-6a97aa35d273)
•
ViT는 Transformer를 Vision에 적용한 기법입니다.
•
이미지를 에서 로 변환하여 입력으로 사용합니다.
•
하지만 큰 파라미터 수를 필요로 하는 한계가 존재하여 edge device, mobile에서 사용이 어렵습니다.
◦
큰 모델을 큰 데이터셋으로 학습시키면 일반적으로 성능이 향상되지만, 작은 모델을 큰 데이터셋으로 학습시키면 일반적으로 under-fitting이 발생합니다.
◦
TinyViT의 저자는 작은 모델이 큰 데이터셋으로부터 지식을 흡수할 수 있는 방법에 대해 고민하였습니다.

3. TinyViT
Microsoft Research
Accepted by ECCV 2022
3-1. Introduction
-5.png&blockId=5751725d-220b-4a05-bd48-50abcfe58994)
-6.png&blockId=b8df0c3f-6031-4903-aaea-d26ddff87c4c)
-7.png&blockId=1fba09e9-8bee-4a09-83e9-f6315f3ab628)
-8.png&blockId=30d765ea-c986-454c-83a6-c3df7190f6b7)
•
w/o pretrain
◦
일반적인 작은모델의 작은 데이터셋에 대한 학습방법입니다.
•
w/ pretrain
◦
큰 데이터셋으로 pretrain한 뒤, 작은 데이터셋으로 fine-tune하는 방법입니다. 이 방법은 일반적으로 성능이 향상되지만, 작은 네트워크의 경우 성능 향상에 한계가 나타납니다.
•
w/ pretrain & distillation
◦
큰 데이터셋으로부터 학습된 teacher model로 증류를 수행한 뒤, 작은 데이터셋으로 fine-tune하는 방법입니다. 본 논문에서 제안된 기법으로, 소형 모델에서의 큰 pretraining 데이터의 잠재력을 열 수 있습니다.
Contributions
•
큰 데이터셋을 완전히 활용하여 소형 모델의 수용력을 해방시킬 수 있는 fast pre-training distillation 프레임워크를 제안합니다.
•
연산량과 성능 사이에서 좋은 trade-off를 이루는 새로운 TinyViT 모델을 제안합니다.
3-2. TinyViT
1) Fast Pretraining Distillation
•
일반적으로 KD 학습을 느리게 하는 요인 두 가지
◦
teacher 모델을 로드한 채 student를 학습합니다.
◦
distillation loss 수행 시 soft한 정도를 조절하는 파라미터 T에 대한 연산이 발생합니다.
TinyViT는 위 두 요인을 다음의 방법들로 해소하였습니다.
•
Loss
◦
가 아닌 와의 CrossEntropy loss만을 사용합니다. 때문에 GT label이 없어도 학습이 가능하며, 학습 중 번거로운 T가 제거되기 때문에 distillation을 사용하지 않는 일반적인 모델의 학습만큼 빠릅니다.
: image
: Augmentation
: Teacher model
: Student model
-9.png&blockId=749006fe-36fb-4688-b9a1-e1d390dd313e)
효율적으로 teacher의 output과 augmentation을 저장하는 TinyViT의 저장 기법을 나타냅니다.
•
Sparse soft labels
◦
teacher의 출력을 압축시키는 역할을 수행합니다.
◦
정확하게는, teacher가 출력한 classes 중 top-K values만을 취하고 나머지는 평균내어 저장합니다.
-10.png&blockId=0eb32766-332e-4fbe-8e6e-a57acfbbfca3)
•
Data augmentation encoding
◦
teacher의 출력을 저장하는 것도 중요하지만, 입력값을 저장하는 것도 중요합니다. augmentation 용량을 줄이기 위해 인코더를 도입하고, 인코딩된 결과값을 저장합니다.
2) Model Architecture
-11.png&blockId=eaeb9429-2533-433e-b4a7-24098f4177d4)
Figure 3. (a) The architecture of a Swin Transformer (Swin-T)
https://arxiv.org/pdf/2103.14030.pdf
•
점진적으로 해상도가 감소되는 4단계 모델을 기반으로, factor를 통한 축소가 가능하도록 설계되었습니다.
◦
: 4개 스테이지 각각의 dimension
◦
: 4개 스테이지 각각의 블록 수
◦
: 2, 3, 4 스테이지의 window size
◦
: MBConv 블록의 채널 확장 ratio
◦
: 모든 transformer 블록에 대한 MLP의 expansion ratio. (줄이면 MLP의 hidden dim이 작아집니다.)
◦
: multi-head attention에서 각 헤드의 dim. (줄이면 head 수가 증가하여 computation cost가 절감됩니다.)
3-3 Experiments
-12.png&blockId=91c3bfbd-22e6-4995-bd2e-42963155feb1)
•
TinyViT는 타 classification methods보다 적은 파라미터에서 높은 성능을 제공하는, 좋은 trade-off를 보여줍니다.
•
또한, 추론 속도면에서도 좋은 trade-off를 보여줍니다.
-13.png&blockId=cf4124e2-a85c-43a5-98f2-dd45746518f5)
•
파라미터 별로 모델을 분류하여 성능을 평가한 테이블입니다. 이전 methods보다 더 높은 성능으로 SOTA를 달성했습니다.
-14.png&blockId=1a96af37-f7c4-4630-8355-b88b00897ee9)
•
Classification이 아닌 Detection method에 적용했을 때에도 Baseline 대비 개선된 성능을 보여줍니다.
4. Image Generation
생성한 이미지를 학습 데이터로 활용한 학습의 실효성에 대해 검토 중에 있습니다.
txt2img - Add Style
-15.png&blockId=ae3f1040-5920-40db-bb5c-3f40a7c3bb4f)
•
텍스트로 스타일을 Generation하고, 스타일에 텍스트를 추가하여 이미지를 Generation한 샘플입니다.
img2img
-16.png&blockId=837dbda1-55c5-40fe-a8fe-d50f61aefdc5)
•
이미지에 텍스트를 추가하여 이미지를 Generation한 샘플입니다.
List
Search




OGQ GYN의 기술블로그를 비상업적으로 사용 시 출처를 남겨주세요.
상업적 용도를 원하실 경우 문의 부탁드립니다.
E-mail. tech@gynetworks.com
 OGQ Corp. All right reserved.
OGQ Corp. All right reserved.