

OGQ GYN Developers Day는 OGQ GYN의 모델 개발 과정 및 논문 등을 많은 기업 분들께 발표하는 자리로, 매월 마지막 주 수요일에 진행되고 있습니다.
이번 세미나에서는 Model Compression 기법 중 하나인 Knowledge distillation과 최신 논문에 대하여 소개해드리고, 개발 현황 및 향후 개발 방향을 발표했습니다.
Contents
세미나 개요
•
일시 : 2022년 9월 28일 13:00 ~ 14:00
•
장소 : Zoom 미팅
•
참여기업 (가나다순)
◦
베스트디지탈 BEST DIGITAL
◦
아이닉스 Eyenix
◦
에스카 ESCA
◦
웹게이트 WEBGATE
◦
케이티 KT
◦
트루엔 TRUEN
•
순서
1.
참여 업체 소개
2.
OGQ GYN 발표
•
사회자: OGQ GYN 우재현 연구원
•
발표자: OGQ GYN 정재희 연구원
3.
Q&A
1. Previous Presentation Summary
지난 컨퍼런스에서는 Fire Classification 모델의 성능과 수자원공사 현장 적용 사례를 소개하고, 개선 방향에 대하여 공유해드렸습니다.
-4.png&blockId=3b0d8fbc-5d90-419a-8aeb-dded750b2af3)
#Multi-class classification(불꽃, 연기 예측), binary-class classification(불꽃, 연기 구분 없이 예측
-5.png&blockId=07537211-0161-4ec5-9073-df40597352aa)
#K-water 화재 sever 적용, 99.65% 오검출 개선
1-1. 수자원공사 현장 적용
_Tech_(7)-3.png&blockId=c8ac04dc-5858-43a2-9865-b15d9be1995b)
수자원공사에 화재 Server 타입을 적용한 결과
•
적용 초기에 야간 순찰, 불빛, 빛번짐 등으로 인해 오검출이 발생하였습니다.
1-2. 개선 방향
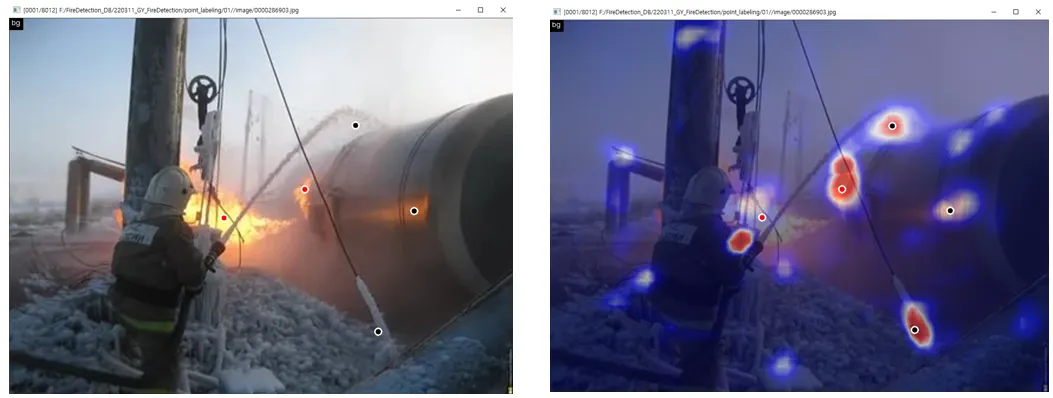
point annotation example
1.
Label noise 문제를 해결 가능하다면 Detection 모델로 다시 개발을 하는 것이 좋을 수 있다고 판단하였고, inductive bias 문제를 higher annotation 및 point annotation을 기반으로 해결하려 하고 있습니다.
2.
Classification model 기반으로 확보된 weight는 Self-attention 구조 추가 및 Semi-supervised learning 기법으로 개선 예정입니다.
3.
추가 데이터셋 또는 Server, EN675 모델 간의 성능 차이를 줄일 수 있는 기법을 적용하여 다음 버전 배포 예정입니다.
2. Knowledge Distillation
2-1. 기존 모델
_Tech_(7)-4.png&blockId=ecdf3979-fcc9-48ca-bd99-2f2d1b0dda70)
•
기존 딥러닝 모델을 학습시킬 때에는 입력에 대하여 모델이 예측 결과를 만들고, 이 예측 결과와 label을 대조하여 학습시키는 방법을 사용했습니다.
_Tech_(7)-5.png&blockId=ac448ff8-785f-4b12-93db-f74ec4c28cfd)
•
하지만 이렇게 학습 시킨 모델은 모델의 크기에 따라서 장단점이 있습니다.
•
작은 모델의 경우 빠른 추론 속도를 가지고 있어 배포 환경에 적합하지만 낮은 정확도를 가지고 있습니다.
•
큰 모델의 경우 추론 속도가 느려 배포 환경에 부적합하지만 높은 정확도를 가지고 있습니다.
이러한 문제를 해결하기 위해 큰 모델의 정확도를 유지하면서 빠른 추론 속도를 가진 모델을 만드는 Model compression 기법들이 제안되었습니다.
1.
모델의 각 weight의 용량을 줄이는 Quantization
2.
모델에서 중요하지 않은 weight를 삭제하는 Pruning
3.
큰 모델의 지식을 작은 모델로 옮기는 Knowledge distillation
2-2. Knowledge Distillation
_Tech_(7)-6.png&blockId=bb3a32f0-b5fa-4896-9717-2e56fb73d50d)
•
Knowledge Distillation은 NIPS 2014에 제출된 Distilling the Knowledge in a Neural Network라는 논문에서 제시된 개념입니다.
•
기존의 모델을 학습할 때와는 달리, 다른 학습이 된 큰 네트워크의 출력 결과를 추가로 label로 사용하여 작은 모델을 학습시키는 것입니다.
•
이때 큰 네트워크를 teacher, 작은 네트워크를 student라고 부릅니다.
•
큰 모델의 지식을 작은 모델으로 전달(증류)하는 것과 같아 Knowledge distillation이라는 이름이 붙었습니다.
3. CWD
_Tech_(7)-7.png&blockId=72fff7e0-548c-4739-8394-cca6b4c336ae)
•
CWD(Channel-wise Knowledge Distillation)은 ICCV 2021에 제출되어 2021년 SOTA를 달성한 Semantic segmentation을 위한 Knowledge distillation 기법입니다.
_Tech_(7)-8.png&blockId=9f92d741-5022-49fb-b8ba-536bce1e6ad0)
•
기존의 Semantic segmentation knowledge distillation 기법은 모델이 생성하는 이미지와 객체의 특징이 담긴 feature map에 대하여 각 픽셀 별로(W * H) teacher의 결과를 따라할 수 있도록 만들었습니다.
•
CWD는 feature map의 각 채널(C)이 이미지에 포함되는 객체 영역을 나타낸다는 것을 발견하고, 이를 기준으로 결과를 따라하도록 만들었습니다.
_Tech_(7)-9.png&blockId=78053048-4dc9-499a-b2ba-60bc5a962077)
•
CWD는 다른 knowledge distillation method들보다 학습 속도도 빠르면서, 이전 SOTA method들의 성능을 뛰어넘었습니다.
_Tech_(7)-10.png&blockId=88e47869-1c25-4c8e-8053-facd0b02f320)
•
Semantic segmentation 뿐만 아니라 Object detection에 적용했을 때에도 가장 높은 성능을 달성한 것을 확인할 수 있습니다.
4. Development Status
4-1. Current Status
_Tech_(7)-11.png&blockId=012c0263-3ef5-4685-bfa7-ad266f4bcb72)
WSSS를 이용한 bounding box 생성
•
이전에 배포했던 Fire classification 모델을 기반으로 Segmentation 및 detection 모델을 개발 중에 있습니다.
•
자체 WSSS(Weakly Supervised Semantic Segementation) 기술을 이용하여 tag 정보가 있는 이미지에 대해서 mask를 생성한 뒤, mask 기반 bounding box 생성하여 학습하게 됩니다.
•
이를 통해 label 생성이 힘든 segmentation mask를 tag label로 생성 가능하기 때문에 학습에 더 많은 데이터를 이용할 수 있고, 효율적인 학습이 가능해집니다.
4-1-1. RS+EPM
_Tech_(7)-12.png&blockId=ea0d6753-f349-452f-9e37-99009eddc4ff)
RS+EPM Framework
_Tech_(7)-13.png&blockId=7b97adc8-8200-4045-92a8-5588802996bc)
데이터셋 별 최고성능 모델
_Tech_(7)-14.png&blockId=3b89f114-a5f0-4732-ae9b-e8270eb136b7)
PASCAL VOC 2012 val 순위
_Tech_(7)-15.png&blockId=b7598104-81a6-4cc8-a002-2d640c22a82b)
PASCAL VOC 2012 test 순위
_Tech_(7)-16.png&blockId=25dc5d82-5e9d-4502-8406-bf84588d46bb)
COCO 2014 val 순위
•
RS+EPM은 OGQ GYN의 자체 WSSS 기술으로, 현재 모든 데이터셋 기준 가장 높은 성능을 달성하고 있는 프레임워크입니다.
4-2. Future Development
_Tech_(7)-17.png&blockId=1cea2fe7-f2e0-4a26-879c-551dfb3149aa)
_Tech_(7)-18.png&blockId=8d6d4f3e-8886-4187-b395-0577f82019e2)
•
학습시키는 detector의 성능을 더욱 끌어올리기 위하여 데이터를 더욱 많이 사용할 필요가 있습니다.
•
현재 bounding box가 있는 데이터의 수는 36K, bounding box와 tag가 있는 데이터가 110K, label이 없는 데이터가 4M개 있습니다.
•
이 데이터들을 모두 활용하여 detector를 학습시키기 위하여 classifier가 화재가 있다고 감지했을 때, RS+EPM을 활용하여 pseudo box label을 만들어 학습을 진행중입니다.
•
또한 앞서 설명드린 knowledge distillation을 적용하여 Server타입과 EN675타입의 성능 격차를 줄이려 하고 있습니다.


•
실제 이미지가 아는 Image Generation AI를 이용하여 생성한 이미지를 학습 데이터에 포함시켜 학습했을 때 효과가 있는 지 내부적으로 검토 중에 있습니다.
List
Search




OGQ GYN의 기술블로그를 비상업적으로 사용 시 출처를 남겨주세요.
상업적 용도를 원하실 경우 문의 부탁드립니다.
E-mail. tech@gynetworks.com
 OGQ Corp. All right reserved.
OGQ Corp. All right reserved.