

OGQ GYN Developers Day는 OGQ GYN의 모델 개발 과정 및 논문 등을 많은 기업 분들께 발표하는 자리로, 매월 마지막 주 수요일에 진행되고 있습니다.
이번 세미나에서, 일 5억건 대규모 트래픽 Tag-AI API 구축 스토리와 고려할 점 3가지에 대해 소개하였습니다.
Contents
세미나 개요
•
일시 : 2024년 03월 06일 13:00 ~ 14:00
•
장소 : Zoom 미팅
•
참여기업 (가나다순)
◦
베스트디지탈 BEST DIGITAL
◦
웹게이트 WEBGATE
•
순서
1.
참여 업체 소개
2.
OGQ GYN 발표
•
사회자: OGQ GYN 우재현 연구원
•
발표자: OGQ GYN 오다연 연구원
3.
Q&A
따라서 우리는 OGQ 자체 태깅 모델을 활용하여 이미지 설명이 가능한 태그 정보를 획득하고, 이 정보를 LLM의 입력으로 사용합니다.
이는 언어모델이 이미지를 보고 추론하는 것과 유사한 효과를 지닙니다.
1. Previous Presentation Summary
지난 컨퍼런스에서는 추론 속도가 개선된 OGQ GPT V1.1을 소개드렸습니다.
기존 구조의 경우, LLM에 사용할 이미지 정보로 ImageEncoder의 Output을 사용합니다.
이 Output이 클수록, 추론 속도가 저하되는 현상이 있습니다.
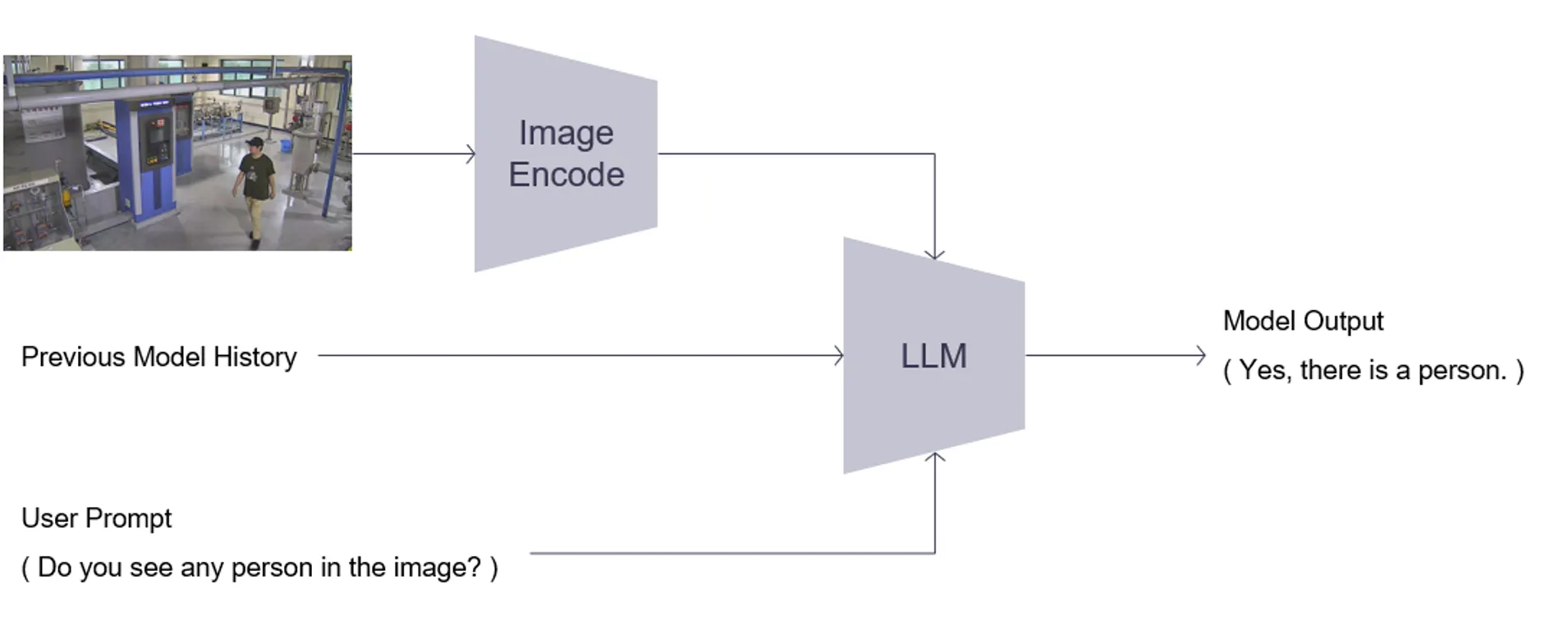
OGQ GPT V1.0
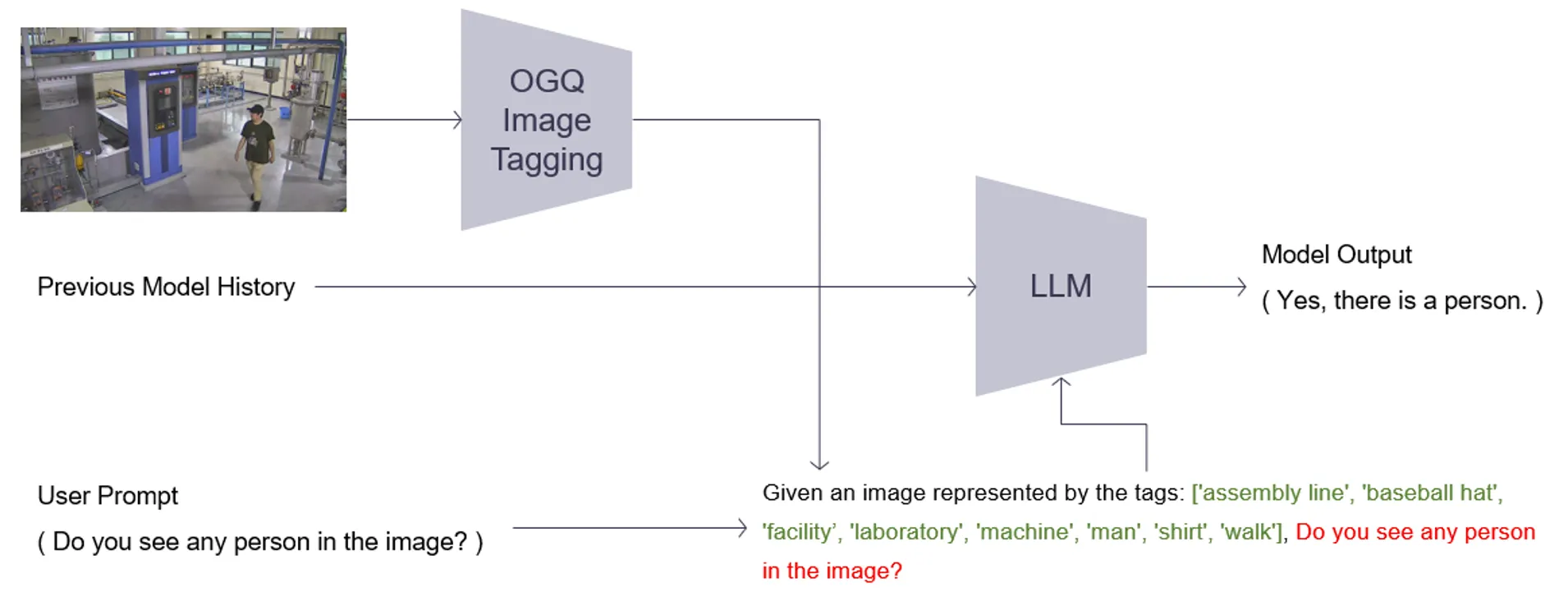
OGQ GPT V1.1
그 덕분에 적은 Computation Cost를 사용하여, 기존 모델 대비 6배 빠른 추론 속도를 달성합니다.

OGQ GYN의 채팅 AI를 경험해보세요. [Aloha Demo 바로가기]

2. Objective
OGQ GYN의 Tagging AI 기술은 NAVER CLOUD 사의 MYBOX에 공급되고 있습니다.
목적은 Tagging AI를 활용하여 데이터베이스에 태그 정보를 추가하고, 텍스트를 통한 이미지 검색 기능을 개선하는 것입니다.

MYBOX 팀이 우리의 모델을 사용하는 과정은 크게 4 단계로 구성됩니다.
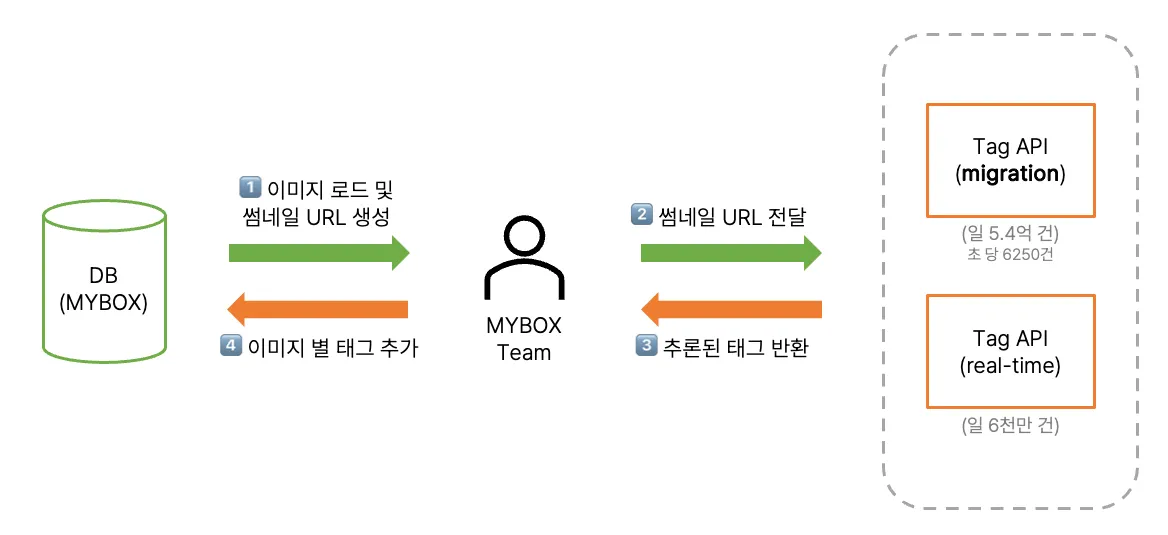
우리의 API는 마이그레이션용과 실시간용으로 구분됩니다.
(본 포스트는 트래픽이 큰 서비스인 migration API 기준으로 설명합니다.)
우리의 목표는 초 당 6250건의 트래픽을 감당할 수 있는 TagAPI를 만드는 것입니다.
3. Scale-Out
저희는 AI 체험 서비스 프로젝트에서의 AI API 개발 경험을 바탕으로, 쉬운 방법 중 하나인 서버 대수를 확장하는 방법을 먼저 시도해보았습니다. 이를 Scale-Out이라 하는데요. 조금 더 쉬운 예시로 설명해보겠습니다.
OGQ GYN의 AI 기술을 체험해보세요. [DeepManager 바로가기]
3-1. Scale-Up & Scale-Out
우리가 식당에 가서 김치찌개 1인분을 주문합니다.
요리사는 작은 크기의 냄비를 사용하여 찌개를 준비할 수 있을 것입니다.
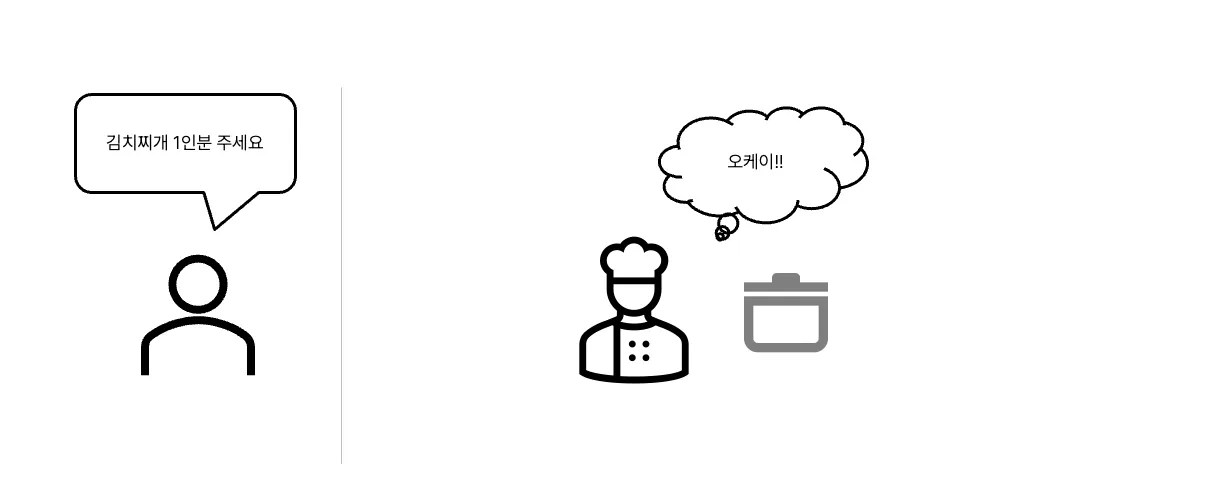
주문량이 2배로 늘어난다면 어떻게 될까요?
요리사는 조리 도구로 작은 크기의 냄비 2개를 사용하거나, 큰 냄비 하나를 선택할 수 있습니다.
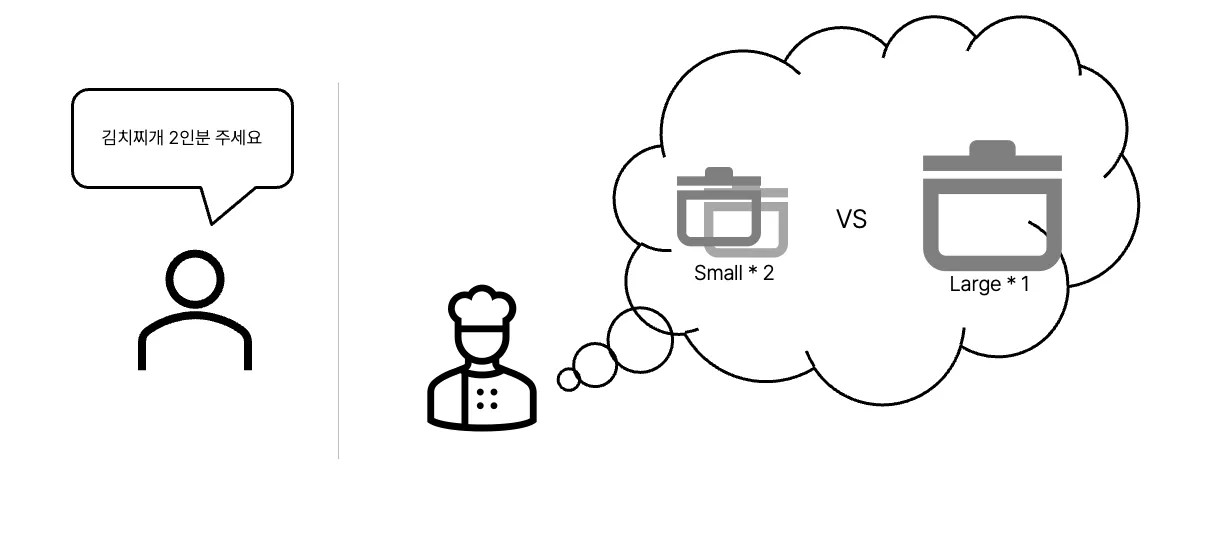
여기서, 작은 냄비 두 개를 선택하는 방법을 Scale-Out, 큰 냄비를 선택하는 방법을 Scale-Up이라 할 수 있습니다.
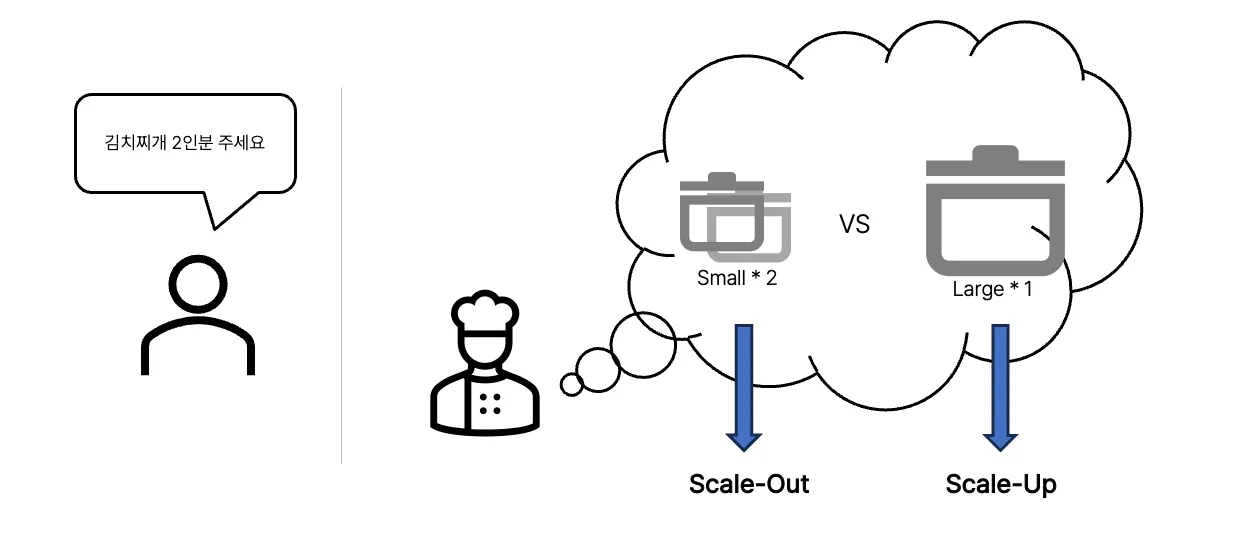
Scale-Out? Scale-Up? 어떤 것이 좋은 방법일까요? 2인분의 경우 모두 선택할 만 해 보입니다.
그렇다면, 주문량을 1,000배로 늘려볼까요?
1,000인분을 소화할 수 있는 냄비는 흔하지 않습니다. 있더라도 큰 비용을 지불해야할 것입니다.
따라서 이런 경우, 작은 크기의 냄비를 1,000개 사용하여 1,000인분을 준비할 수 있습니다.
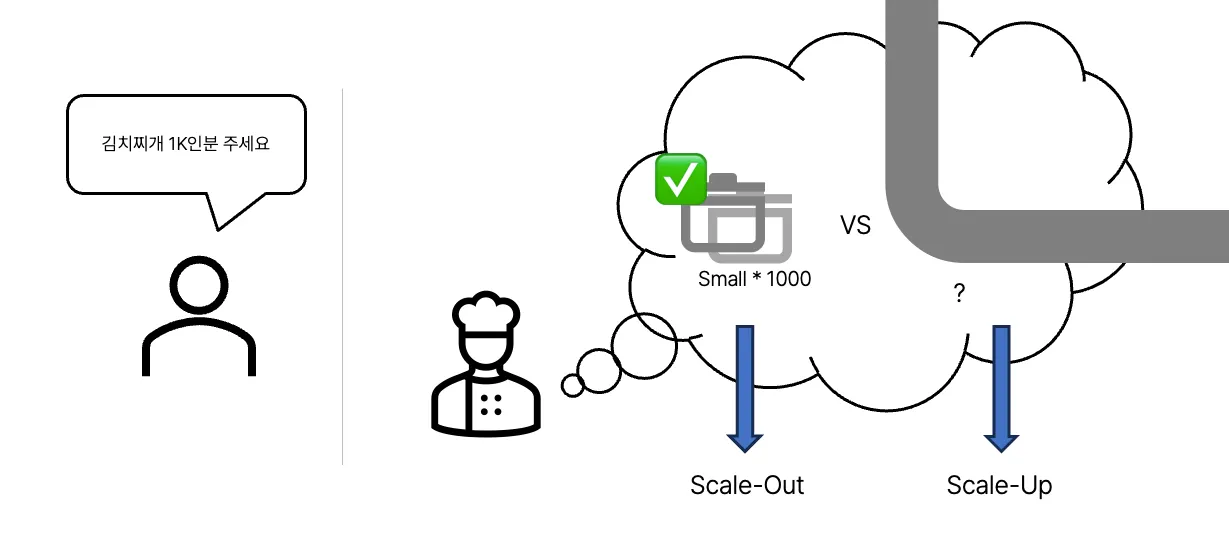
또는 둘을 혼합하여 중간 크기의 냄비 500개를 선택할 수도 있겠죠? 효율적인 비용의 장비를 사용하는 것이 중요합니다.
3-2. Implementation
실제 반영 과정에서는 분산 처리 적용이 필요합니다. 여러 대의 서버에 트래픽을 효율적으로 나누어야 하기 때문이죠. 적절한 사양의 서버 선택과, 분산 처리 적용에 대해 설명드리겠습니다.
모델의 추론 속도는 서버 사양. 그 중에서도 GPU 사양에 의해 큰 차이가 발생합니다.
서버 사양 별 API 성능 및 비용은 다음과 같습니다.
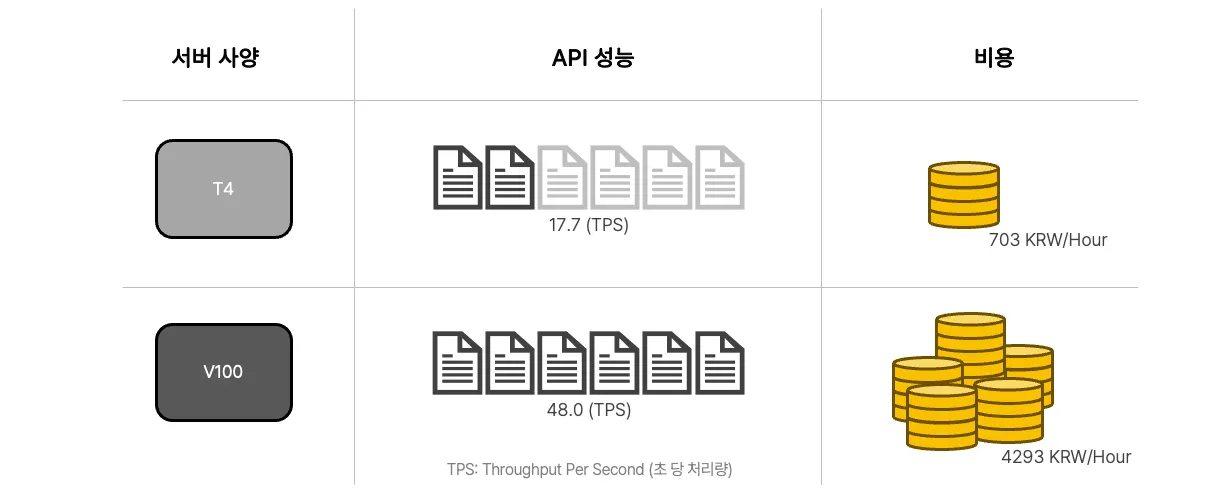
우리의 애플리케이션은 T4 사양에서 좋은 효율을 보여줍니다.
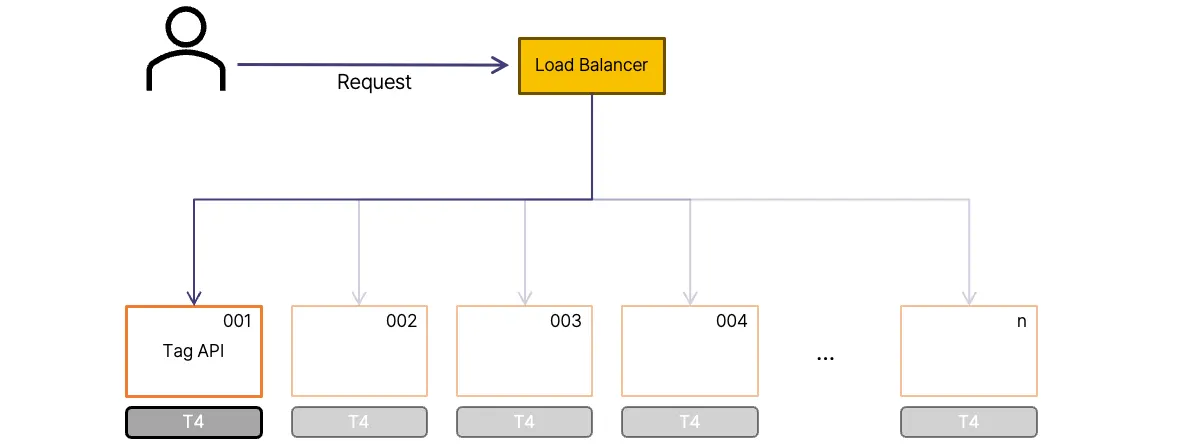
따라서, T4 인스턴스를 다중 사용한 부하분산이 필요합니다. 이를 위해, 필요한 성능만큼 인스턴스를 실행했습니다.
그리고, 요청을 여러 서버에 Load Balancer를 통해 분배합니다. 분산 방법은 다양하지만, 순서대로 분배하는 Round Robin을 사용하였습니다.
하지만 실제 배포과정에서 응답 지연 현상을 겪었습니다. 그리고, 첫번째 고려할 점을 마주하게 됩니다.

3-3. Issue
시간 지연 이슈에 대한 원인을 파악한 과정을 설명드리겠습니다.
서버 내 처리 순서는 다음의 단계로 구성됩니다.
1.
이미지 URL을 수신
2.
이미지 다운로드
3.
AI 추론
4.
추론된 태그 반환
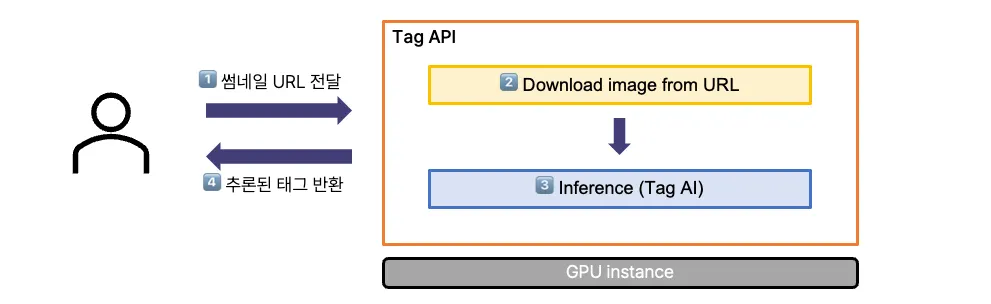
초기에는 4에 대한 로그 위주로 집계하였고, 이로 인해 시스템 상황 이해에 어려움을 겪었습니다.
기존의 성공/실패 위주의 로그에서 2&3에 대한 로그를 강화하여, 시스템 상태를 관찰 가능하도록 개선하였습니다.

그 결과 다운로드 과정에 지연이 존재하며, 추론이 목표치의 약 10% 정도만 동작함을 확인하였습니다.
여러 기능이 하나의 인스턴스 내에서 동작하고 있어 복잡하였습니다. 때문에 에러 재현 및 해결이 쉽지 않았고, 보다 쉬운 구조로 변경하고자 했습니다.
3. Micro Service Architecture
4-1. MSA
이전의 복잡성을 개선하고자, MSA로 전환을 시도합니다. MSA를 집에 비유하여 설명 드리겠습니다.
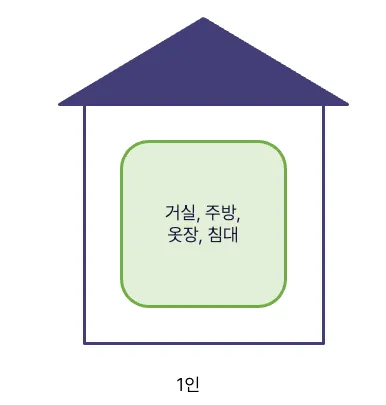
한 명이 거주한다면, 구성 요소는 무엇이 있을까요? 거실, 주방, 옷장, 침대 등이 있을 것입니다. 한 명을 위해 모두 필요합니다.
두 명이면 어떻게 대응할 수 있을까요? 다음과 같은 방법이 있을 것입니다.
1.
각자의 집에서 거주
2.
쉐어하우스에서 거주
쉐어하우스의 경우, 특정 구성 요소를 함께 사용합니다. 또한, 수용 인원에 대해 유연한 편이라고 볼 수 있습니다. 침대를 추가 구비한다면, 일부 침대가 고장나도 생활이 가능하며 외부인이 며칠 거주해도 큰 지장 없이 운영 가능할 것입니다.
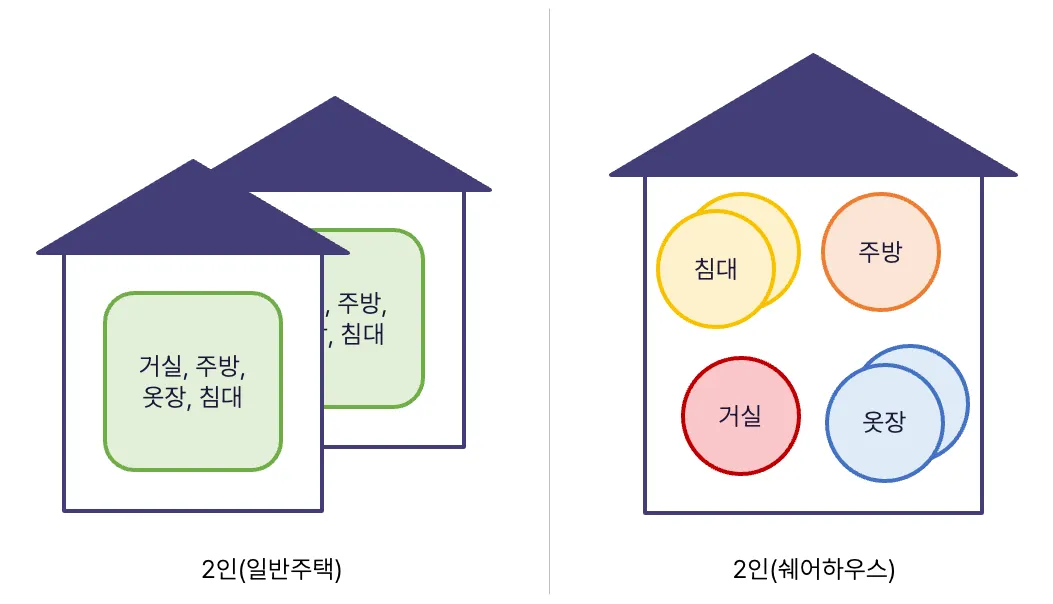
좌측은 이전 시스템 구조와, 우측은 개선하고자하는 구조와 유사합니다.
4-2. Implementation
고려할 점 2, 3은 단순성과 적절한 부하 분산입니다.

기존 설계에서 하나의 서버가 여러 기능을 수행하여 복잡하였고, 이는 유지보수의 어려움으로 이어졌습니다. 이를 해소하기 위해 서비스를 작게 나누어, 유지보수가 쉬운 단순한 구조로 설계를 개선하고자 했습니다.
또한, 요청을 각 서버에 균등하게 분배할 수 있어야합니다. 이를 위해 서버 간 느슨한 연결을 고려하고, 적절한 Load Balancing Algorithm을 선택하였습니다.
다음은 MSA 구조가 적용된 우리의 시스템에 대한 도표입니다. 기능 별로 서비스를 구분하고, 사이에 MQ, Redis 서버를 넣어 느슨하게 연결하였습니다.
각 서버 입장에서 담당하는 기능을 구분하면, 다음과 같습니다.
•
API Server
◦
사용자가 전달한 URL로부터 이미지를 다운로드 후, RabbitMQ에 Publish합니다.
◦
분석 결과를 가져올 수 있도록, Redis를 subscribe합니다. 가져온 분석 결과를 사용자에게 반환합니다.
•
AI Server
◦
분석할 이미지가 저장된 RabbitMQ를 subscribe합니다. 가져온 이미지를 분석합니다.
◦
분석 결과를 Redis에 publish합니다.
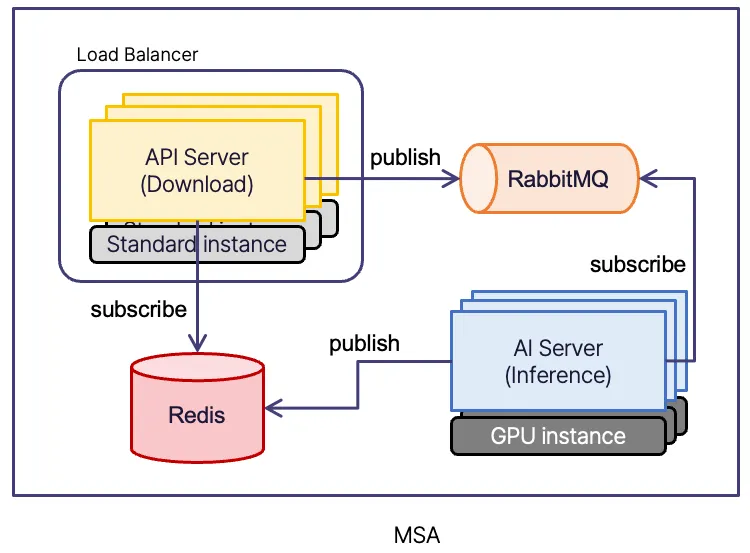
장단점은 다음과 같습니다.
•
장점
◦
각 서버에서, 하나의 기능만을 담당하여 단순함.
◦
Scale-Out이 가능함.
◦
일부 AI Server가 죽더라도 정상 동작.
◦
peak 발생에도 비교적 안정적임.
•
단점
◦
모니터링 포인트 증가
◦
배포 복잡성 증가
Load Balancing Algorithm
Least Connection으로 알고리즘을 변경하였습니다. (기존: RoundRobin)
이 방법은 활성 연결이 가장 적은 서버로 트래픽을 전달합니다. 비교적 여유 있는 서버에 작업을 할당해주는 것이죠.
(RoundRobin은 서버에 동일한 부하를 주는 방법으로, 효율적으로 보일 수 있습니다. 하지만 서버 별 처리 시간은 항상 동일할 수 없고, 특정 서버에 요청이 누적되는 현상이 발생할 수 있습니다)
비로소 처리해야할 작업들을 서버에 효율적으로 분배할 수 있게 되었습니다.
4-3. Performance
320대의 동일 장비에서, 초기 처리량 대비 892%의 향상을 달성할 수 있었습니다.
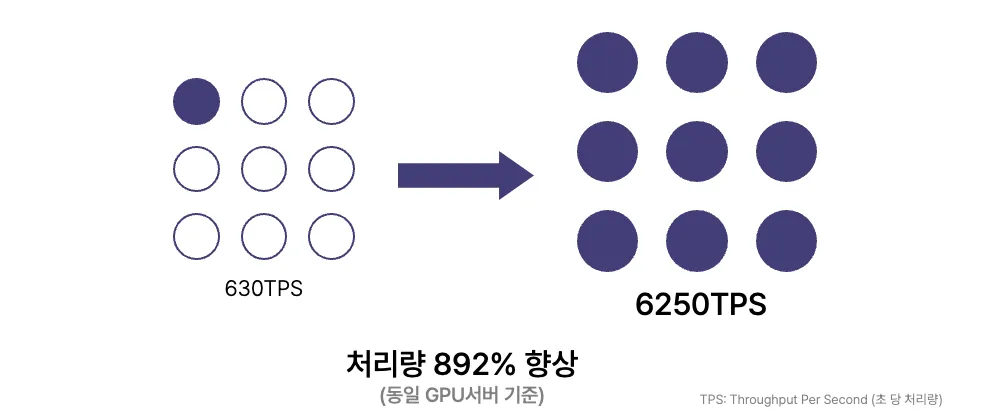
5. 마치며
본 포스트에서는 일 5억건을 처리하는 AI API 설계 및 고려할 점에 대해 정리해보았습니다.
대규모 트래픽을 감당하기 위해, 고성능 인프라와 함께 효율적이고 안정적인 시스템 아키텍처가 필수적임을 다시금 확인할 수 있었습니다. 기술 및 비용 요구 사항을 충족시키기 위해, AI 분석을 효율적으로 처리하는 것은 핵심적인 과제입니다. 동향 및 기술적 발전을 연구하여, 보다 개선된 서비스를 제공할 수 있는 방법을 모색할 것입니다.
감사합니다.
List
Search




OGQ GYN의 기술블로그를 비상업적으로 사용 시 출처를 남겨주세요.
상업적 용도를 원하실 경우 문의 부탁드립니다.
E-mail. tech@gynetworks.com
 OGQ Corp. All right reserved.
OGQ Corp. All right reserved.