
OGQ GYN Developers Day는 OGQ GYN의 모델 개발 과정 및 논문 등을 많은 기업 분들께 발표하는 자리로, 매월 마지막 주 수요일에 진행되고 있습니다.
이번 세미나에선 Inpainting task 및 CVPR 2022에 accept된 논문인 Blended Diffusion을 소개해드렸습니다.
Contents
세미나 개요
•
일시 : 2023년 04월 26일 13:00 ~ 14:00
•
장소 : Zoom 미팅
•
참여기업 (가나다순)
◦
베스트디지탈 BEST DIGITAL
•
순서
1.
참여 업체 소개
2.
OGQ GYN 발표
•
사회자: OGQ GYN 우재현 연구원
•
발표자: OGQ GYN 정재희 연구원
3.
Q&A
1. Previous Presentation Summary
지난 컨퍼런스에서는 Image Semantic Segmentaiton 기법을 그대로 프레임을 분리하여 Video Semantic Segmentation에 적용시켰을 때 발생하는 Consistency 문제를 해결하기 위한 프레임워크인 AuxAdapt와 그 성능에 대해서 설명드렸습니다.

Image Semantic Segmetnation 기법을 그대로 영상에 적용시켰을 때 발생하는 문제
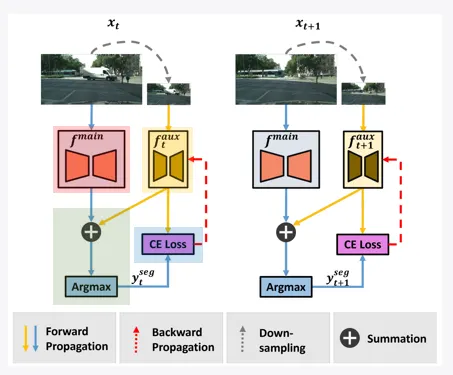
보조 네트워크를 추가하여 consistency 문제를 해결한 AuxAdapt

왼쪽 위: AuxAdapt를 사용하지 않았을 때, 왼쪽 아래: AuxAdapt를 사용하여 consistency 문제가 해결된 모습
2. Inpainting
일반 Inpainting
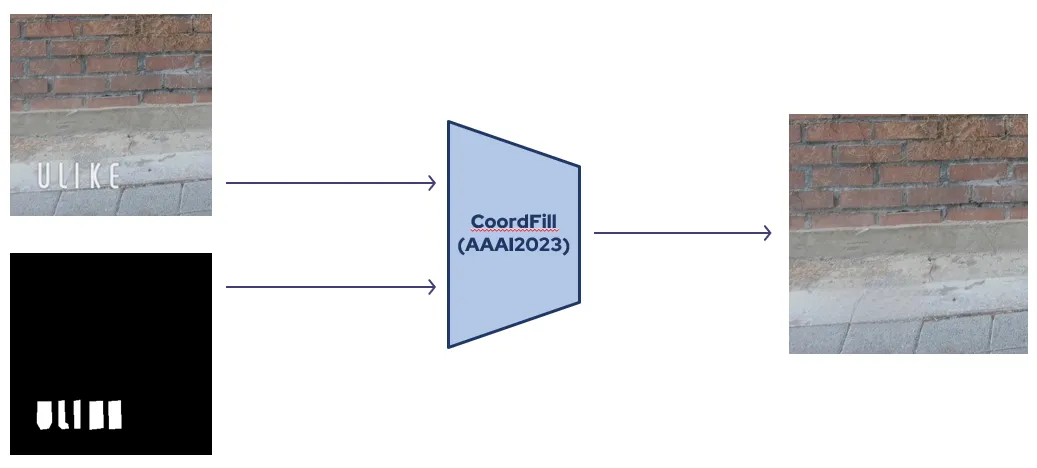
•
Inpainting이란 주어진 이미지에서 원하는 객체 또는 영역을 자연스럽게 채워주는 task입니다.
•
위 그림은 실제 CoordFill이라는 inpaining 모델을 사용하여 생성한 이미지로, 입력으로 함께 주어진 mask에 해당하는 부분을 자연스럽게 채워주는 모습을 확인할 수 있습니다.
Prompt-conditioned Inpainting

•
일반적인 Inpainting은 원하는 영역을 자연스럽게 채워주기만 할 뿐 어떤 객체를 어떻게 채워줄지는 지정해줄 수 없습니다.
•
Prompt-conditioned Inpainting은 mask 영역에 사용자가 직접 원하는 객체를 텍스트 형태로 입력하여 생성할 수 있습니다.
3. Background

•
기존 프롬프트 기반 inpainting 기법들은 GAN 모델을 이용하였는데, 이러한 기법들은 위 그림과 같이 세 가지의 문제가 있었습니다.
◦
수정을 원치 않는 background 영역에 대한 보존 능력 부족
◦
학습된 데이터에서만 잘 작동하도록 설계됨
◦
원본 보존과 수정 영역을 새로 만드는 것을 동시에 잘 수행하는 것이 어려움
•
이를 해결하기 위해서 Blended Diffusion이 제안됩니다.
•
Blended Diffuison은 DDPM과 CLIP이라고 하는 기존에 존재하는 두 가지 모델을 활용하여 만들어진 모델입니다.
DDPMs (Denoising Diffusion Probabilistic Models)
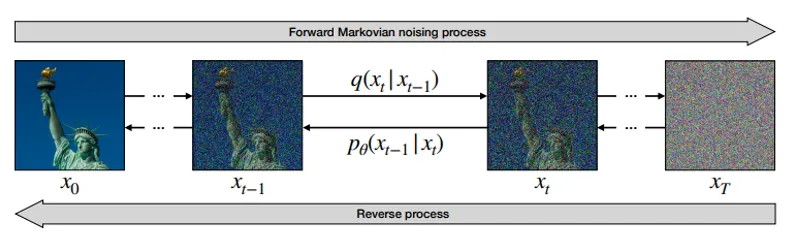
•
DDPM은 샘플 이미지가 있을 때, 여기에 조금씩 노이즈를 더해가며 거의 완전한 노이즈를 생성한 뒤 이를 다시 역으로 복원하는 과정을 학습합니다.
•
이를 통해 학습된 DDPM은 노이즈를 입력으로 받아서 새로운 이미지를 생성할 수 있게 됩니다.
•
기존에 DDPM을 이용하여 프롬프트 기반 이미지를 생성하는 것은 많은 시도가 있었지만 mask 영역에 대해서 국소적으로 생성하는 것은 Blended Diffusion이 최초입니다.
CLIP (Contrastive Langauge-Image Pre-training)

•
CLIP은 4억 개의 이미지-텍스트 쌍을 이용하여 미리 학습된 모델입니다.
•
이미지-텍스트 쌍에 해당하는 두 입력을 받으면 임베딩 간의 유사도가 최대가 되도록, 다른 두 입력을 받으면 임베딩 간 유사도가 최소가 되도록 학습하여 이미지와 텍스트 간의 관계를 모델링할 수 있습니다.
4. Blended Diffusion

•
Blended Diffuison은 위와 같은 프롬프트 기반의 Inpainting을 가능하게 하는 모델으로 CVPR 2022에 accept된 논문이며, 113회 인용되었습니다.
•
Blended Diffusion은 두 가지의 기본적인 목적을 가집니다.
◦
DDPM이 생성하는 영역이 주어지는 텍스트의 조건을 충족하는 것
◦
변경을 원치 않는 background에 대한 변화가 최소화가 되는 것
•
위 목적을 실험하기 위해서 두 가지의 모델을 실험하는데, 배경 영역까지 생성하는 Local CLIP-guided diffusion과 mask 영역만 생성하는 Blended Diffusion입니다.
Local CLIP-guided Diffusion
•
Local CLIP-guided diffusion은 mask 영역과 배경 영역 모두 모델에 대한 loss를 이용하여 조절합니다.

•
CLIP 모델을 활용하여 생성되는 이미지의 mask 영역이 주어진 텍스트와 높은 유사도를 가질 수 있도록 합니다.
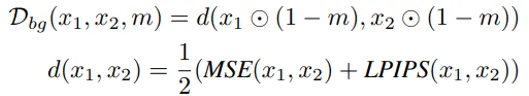
•
background 영역에 대해서는 mask가 아닌 영역에 대해서 원본 이미지와 생성된 이미지 간의 픽셀 유사도(MSE, LPIPS)를 최대화할 수 있도록 합니다.

•
최종적으로 두 loss 간의 값을 이용하여 밸런스를 조절하여 모델을 학습시키게 됩니다.

•
위 과정을 통해서 학습된 모델은 값에 따라서 생성되는 이미지가 달라지게 됩니다.
•
너무 값이 낮을 때에는 background를 잘 보존하지 못하고 완전히 새로운 이미지가 생성되며, 너무 높을 때에는 mask 영역을 잘 생성하지 못하는 모습을 보여줍니다.
•
하지만 적절한 값을 사용하였을 때에도 조금의 background 변화가 발생하기 때문에 다른 blended diffusion을 제안합니다.
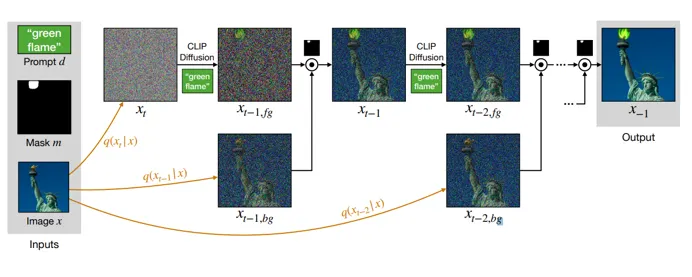
Blended Diffusion
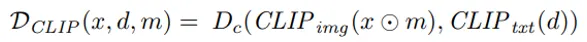
•
blended diffusion에서는 위 세 가지 식 중 첫 번째 식인 mask 영역에 관련된 식만 사용하게 됩니다.
•
blended diffusion은 background 영역에 대해서 모델을 이용하여 생성하지 않고 원본 이미지에 노이즈를 더해 사용하게 됩니다.
•
mask 영역에 대해서 생성한 뒤 이를 노이즈를 더한 원본 이미지와 합쳐준 뒤 다시 mask 영역에 대해 생성하는 과정을 계속하여 반복함으로써 생성되는 영역이 자연스럽게 원본 이미지와 이어지도록 합니다.

Result

•
Blended Diffuison은 객체 뿐만 아니라 배경을 바꾸는 task에서도 자연스럽게 생성할 수 있는 모습을 보여줍니다.
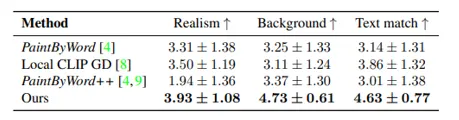
•
사람들에게 0~5로 생성된 이미지를 평가하도록 한 결과입니다.
•
가장 잘 사실적으로 배경을 잘 보존하면서 주어진 텍스트에 맞는 이미지를 생성할 수 있습니다.
Application

•
화재 / 연기 등 원하는 위치에 원하는 객체를 넣을 수 있다는 특성을 이용하여 데이터셋을 증강하고 학습되는 모델의 성능을 향상시킬 예정입니다.